Регулярные выражения (regexp): полный гайд для тех, кто не понимает, как оно работает
RexExp (Regular Expressions) – это универсальный язык для поиска конкретных наборов символов в тексте. Использование регулярных выражений – мастхэв для любого айтишника, хотя бы на самом базовом уровне. Приведем пример: у вас есть логи nginx за последний месяц, и вам нужно точно определить, когда именно сервер выдавал ошибку 40х – 400, 401, 402, 403, 404 и далее. Можно, конечно, самостоятельно перелопатить несколько сотен тысяч строк логов, но на это вам потребуется еще месяц. Что делать? Да, вы можете написать в поиске «400» и записать время, когда появились ошибки; затем написать «401» и сделать то же самое; и так далее. Или вы можете просто написать в поиске, поддерживающем регулярные выражения, «\b40\d\b», и вам выдаст конкретно вхождения в текст 400-409, окруженных пробелами.

Да, механизмы регулярных выражений нужны практически всем айтишникам, но если вы поймаете на улице случайного и спросите его: «Ты знаешь regexp?», с вероятностью 90% он ответит: «Нет». Все дело – в том, что никто толком не знает regexp полностью, эта технология – невероятно сложная, если мы начинаем закапываться в дебри. Эта проблема хорошо описывается популярным мемом:

Из хороших новостей – вам полностью знать regexp и не нужно, для комфортной работы вам надо: 1) привыкнуть к синтаксису регулярных выражений и научиться их читать (пусть и медленно); 2) научиться составлять более-менее сложные шаблоны; 3) знать, как работает метод regexp в вашем ЯП (или каком-либо редакторе, которым вы пользуетесь). Собственно, для этого мы здесь и собрались – ниже вы узнаете всю базу по регуляркам, которая нужна начинающему айтишнику. Для вашего удобства мы разделили темы на уровни: trainee, junior, middle и senior; если вы чувствуете, что какой-то уровень – ваш «предел» на сегодня, то просто отложите следующие уровни на потом (и подумайте, насколько они вам нужны вообще сейчас). После базы вас ждут примеры с разбором и краткий гайд о том, где искать готовые регулярки.
Где будем тестировать – regex101
Регулярки на бумаге выучить невозможно – их нужно писать, их нужно читать. Желательно – чтобы каждый элемент шаблона как-то выделялся, иначе вы быстро запутаетесь в своих же реализациях регулярных выражений, как только они станут более-менее сложными. В сети можно найти несколько подходящих инструментов, но мы остановимся на regex101.com – самом популярном.
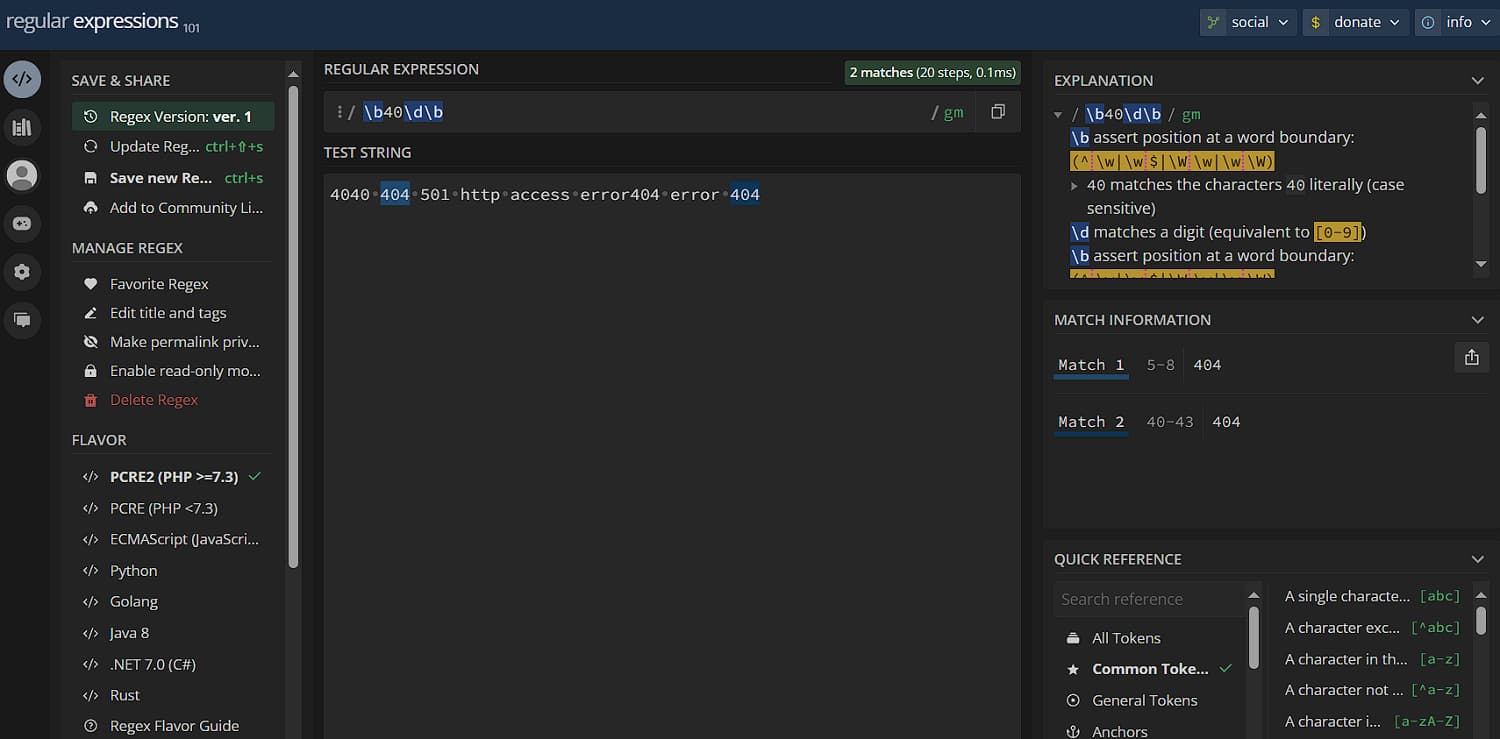
Работает он просто: в верхнем поле вы пишете регулярное выражение, в нижнем пишете текст – и в тексте подсвечиваются все совпадения. В левом меню можно сохранить регулярку (во время обучения вам это не понадобится) и переключить среду (тоже вряд ли пригодится, пусть остается по умолчанию), в правом блоке вы найдете детальный разбор регулярного выражения, полную информацию по каждому совпадению и краткий гайд (раздел «Quick reference») по каждому токену – найдите нужный и кликните по нему.
Если вам regex101.com чем-то сильно не нравится, вы можете пользоваться любым другим инструментом – хоть специальными плагинами в vim; примеры, которые мы будем приводить, будут работать и там. Единственный момент – если вы работаете в какой-то специфичной среде (например, в командной строке Ubuntu), у вас от стандартных могут отличаться глобальные флаги и некоторые токены – все это вы можете уточнить, нагуглив гайд по своей среде (детальнее смотрите на уровне Senior).
Уровень Trainee: ищем символ или слово
Что такое «регулярка»?
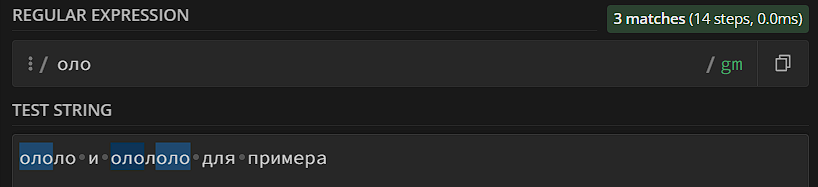
Итак, начнем с самой базы. Что такое регулярное выражение? Регулярное выражение – это язык, с помощью которого описывается шаблон для поиска. Когда шаблон описан, вы даете специальному алгоритму и шаблон, и текст с задачей: «Найди мне текст, который подходит под шаблон». Алгоритм проходится по тексту, находит совпадение/не находит его и возвращает вам какой-то ответ. У алгоритма есть определенные настройки (глобальные флаги) и стили поведения (жадный, нежадный и так далее), но вам это сейчас детально разбирать не нужно, просто запомните – дали алгоритму шаблон, получили совпадение. Единственный момент, который вам нужно сразу знать: один конкретный символ в тексте не может входить в 2 совпадения. Например, ниже мы ищем «оло» в тексте, и вы можете увидеть, что в «ололо» совпадением помечены символы 1-2-3, а вот 3-4-5 совпадением уже не являются, хотя и подходят под шаблон – третий символ уже «занят» другим совпадением.
Самый простой шаблон для регулярных выражений – просто текст. Вероятно, вы пользуетесь такими регулярками, даже если не знаете про них: например, вы можете сейчас открыть «Поиск по странице» и написать что-нибудь в строке поиска, вроде «просто текст». «просто текст» в данном случае и является шаблоном для поиска, вхождением (полным совпадением) будут два слова в конце первого предложения этого абзаца.
Использование regex на таких простых (и понятных) шаблонах далеко не заканчивается – вы можете создавать намного, намного более гибкие вещи. И для того, чтобы научиться их создавать, вам сначала нужно хорошо освоить базовую единицу шаблона – символ.
Символы: обычные, мета-последовательности
Символ – основа любого шаблона, вы всегда ищете символы. В шаблон можно включить любые символы – буквы, числа, пробелы, знаки пунктуации и вообще все, что вы можете придумать. Алгоритму на самом деле неважно, ищете вы «,» или «Ё», для него все это – символы с уникальным индексом.

Если вы ставите несколько символов вместе – алгоритм ищет группу символов, здесь, думаем, пояснения не нужны. Но есть проблема: иногда нам нужно найти не конкретный символ, а что-то из группы символов; или нам вообще не особо важно, какой это будет символ. Например: нам нужно найти все ошибки группы «40x» в логах – с такой задачей мы уже сталкивались в самом начале материала. В этом случае мы можем использовать мета-последовательности: заготовленный диапазон, который мы можем обозначить в шаблоне специальным образом. Самый простой пример мета-последовательности – «.», которая указывает на вообще любой символ:
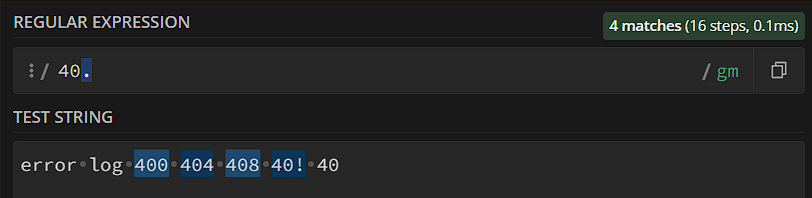
Как видите, алгоритму вообще все равно, что стоит после «40» в тексте, главное – чтобы был еще какой-то символ, тогда он находит совпадение. Если после «40» в конце будет пробел – алгоритм и здесь найдет совпадение, пробел – тоже символ (в regex101 пробельные символы обозначаются серыми кружочками). «.» как мета-последовательность – крайне широкий инструмент, и выше мы можем видеть проблему: «40!» тоже попадает под шаблон, а мы вроде как ищем «400-409». Что делать? Нужно применить более узкую мета-последовательность – \d:
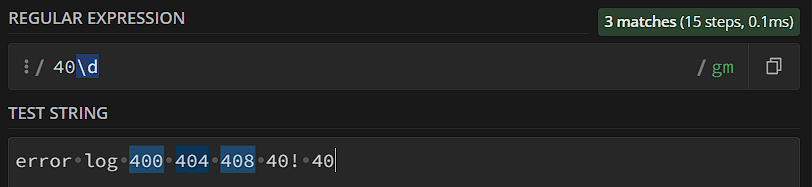
«\d», от слова «digit», указывает на любую цифру – от 0 до 9. У \d есть антагонист – \D, который указывает на любой символ, кроме цифры:
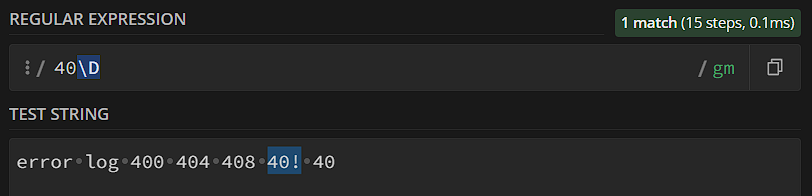
У большинства мета-последовательностей есть такие вот антагонисты, логика всегда одинакова: если буква пишется маленькая – мы ищем какой-то диапазон символов; если буква пишется большая – мы ищем любой символ, кроме этого диапазона. Чаще всего из таких специальных символов применяются:
- \d – любая цифра, от 0 до 9.
- \s – любой пробельный символ.
- \w – любая буква, цифра или знак_нижнего_подчеркивания.
Мета-последовательностей – намного больше, но в типовых regular expressions они используются крайне редко, более детально про них вы сможете узнать в любом cheatsheet.
Мета-символы, экранирование
Мы уже определились, что при поиске совпадений «.» считается любым символом. А что делать, если нам нужно найти конкретно точку?
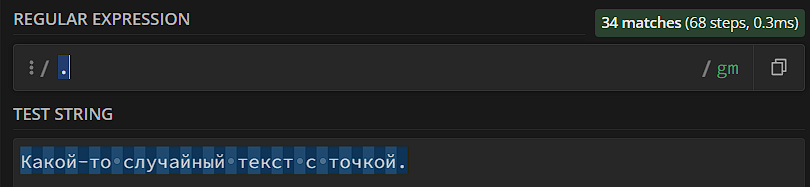
В этом случае нам нужно экранировать точку. В regexp используются мета-символы, которые значат что-то особое: ., +, *, \ и так далее. Если нам нужно вставить в шаблон «обычную» версию мета-символа (без особого значения), мы его экранируем, то есть ставим перед мета-символом обратный слэш (\):
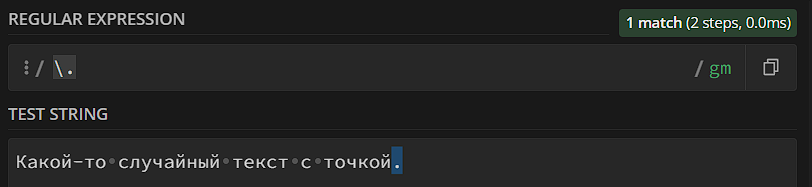
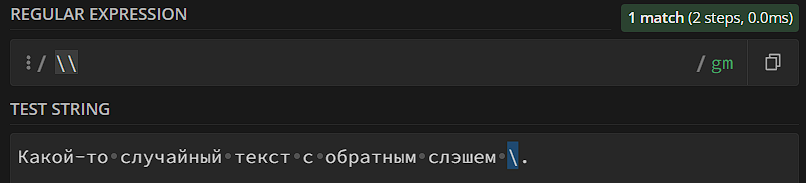
Как вы могли заметить, обратный слэш всегда указывает на то, что надо сделать что-то необычное – мета-последовательности (за исключением точки) мы тоже пишем через обратный слэш (\d, например). А если нам нужно найти обратный слэш в тексте? Его тоже экранируем:
В общепринятой универсальной версии regexp есть 14 специальных мета-символов, вот они:
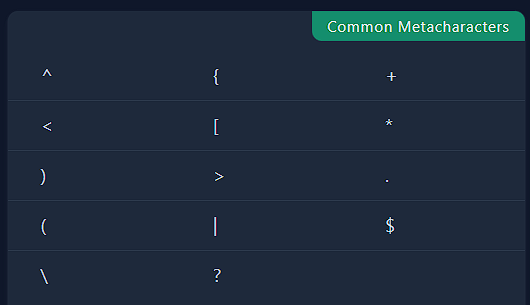
Здесь мы не будем перечислять смысл каждого, вы узнаете о том, как они работают, по ходу обучения. Но вам крайне важно запомнить их все – если вы напишете в шаблоне мета-символ как обычный символ, у вас сломается регулярка.
Уровень Junior: ищем сложное слово, учимся делать выбор
Диапазоны
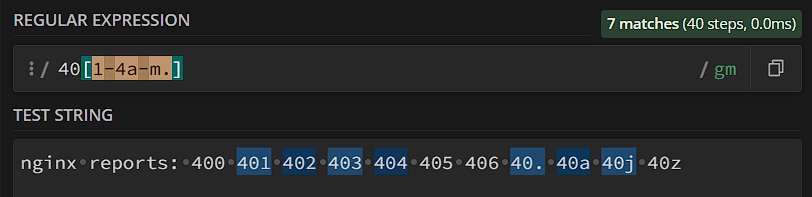
Нам пора познакомиться со скобками – по крайней мере квадратными скобками и круглыми скобками, фигурные мы рассмотрим в разделе «Квантификация». Итак, начнем с более простых – квадратных. Они служат для того, чтобы определить пользовательскую группу обычных символов – то есть мы как-бы сами создаем мета-последовательность (как «.», \d, \w и прочие). Например, выше мы рассматривали случай, когда нам нужно найти ошибки 40х в логах; предположим, что нам теперь нужны только ошибки 402, 403, 404. Обычная мета-последовательность не даст нам нужной гибкости, поэтому создадим более специфичную группу:
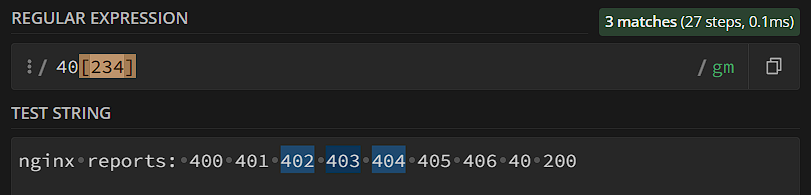
Если мы перечисляем в квадратных скобках несколько символов, то мы говорим алгоритму, что подойдет любой из них – 2/3/4 в данном случае. Запомните: квадратные скобки всегда указывают на то, что мы ищем один символ из тех, которые перечислены в скобках. 3 важные детали, касающиеся квадратных скобок:
- Скобки позволяют вставлять мета-символы без экранирования. У квадратных скобок (которые в англоязычной литературе называются классами) есть свои собственные метасимволы: [, ], \, /,^, -. Вот эти собственные мета-символы групп надо экранировать, а обычные мета-символы, вроде «.», внутри группы экранировать не нужно. «-» можно не экранировать, но лучше ставить его в самом конце класса.
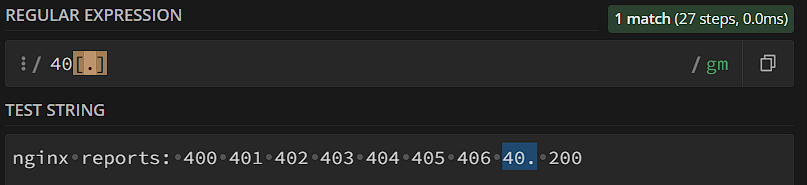
- Квадратные скобки позволяют задавать отрицание. Обычно мы ищем символ, который соответствует любому символу класса; но может случиться так, что нам нужно получить любой символ кроме нескольких. В этом случае нужно поставить ^ первым знаком после открывающей скобки – тогда regexp будет знать, что мы хотим получить любое совпадение, кроме перечисленного в квадратных скобках.
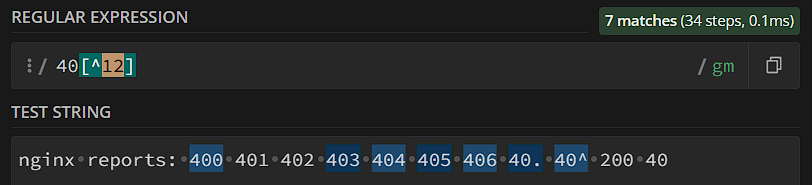
- Внутри классов можно определять диапазоны. Если нам нужны все числа от 0 до 8 – не обязательно их перечислять внутри класса, мы можем задать список символов диапазоном: [0-8]. Диапазон задается мета-символом «-», применять можно для цифр, строчных и прописных букв. Можно использовать несколько диапазонов: [0-5f-jA-X]. Если вам в одном классе нужно описать и несколько диапазонов, и отдельные символы, хорошей практикой будет сначала описывать диапазоны, а потом – символы: [0-27-9a-fz] (от 0 до 2, от 7 до 9, от a до f, 4, z, точка).
Группы
Более детально группы мы будем рассматривать на следующем уровне – они крайне полезны и для квантификации, и для замены/подстановки. Но есть в них польза и для поиска последовательности, поэтому дадим определение: символы, заключенные в круглые скобки, составляют группу. Группа – это подшаблон внутри шаблона, поэтому вы можете использовать, например, классы ([]) внутри группы. Самое интересное в группах на этом уровне – знак «|», который обозначает логическое «или». С помощью знака «|» мы можем указать, что ищем «либо первое, либо второе» (либо третье – знаков «|» может быть несколько):
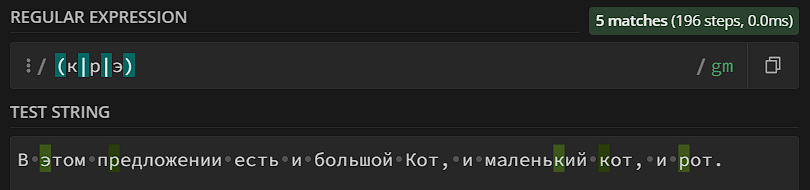
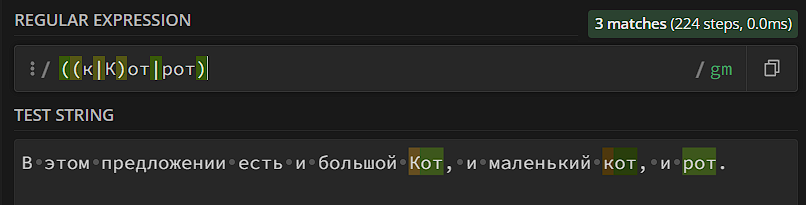
Вам может показаться, что в случае поиска одного из списка символов можно использовать классы ([крэ] вместо (к|р|э)), и вы будете совершенно правы, кроме того – при поиске одного символа из перечисленных лучше использовать классы (квадратные скобки), а не группы (круглые скобки), классы используют меньше ресурсов. Но у групп есть фишка, которой нет у классов: когда вы описываете несколько последовательностей символов внутри группы, алгоритм ищет всю последовательность, а не отдельные символы. Посмотрите на этот пример:
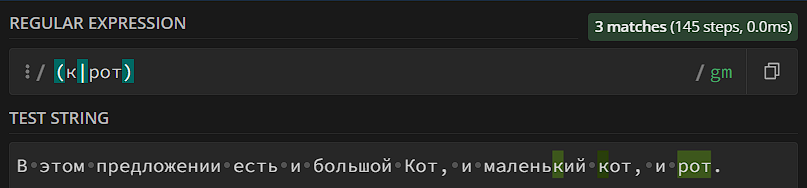
Интуитивно может показаться, что алгоритм должен искать «кот» или «рот» в тексте. Но нет – он ищет либо «к», либо «рот», потому что именно такие последовательности мы задали в группе. Исправим:
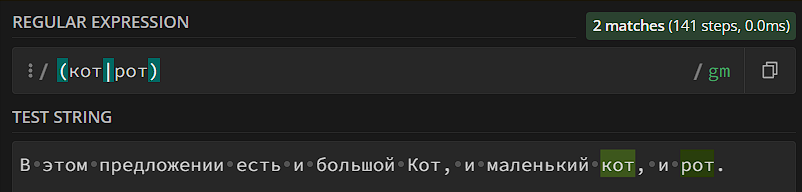
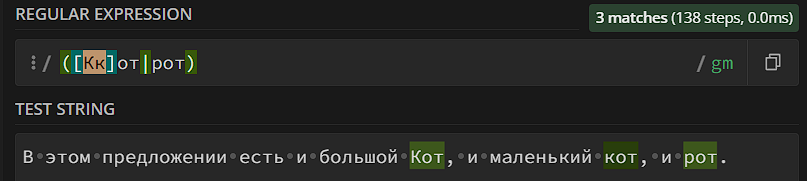
Поскольку группа – это шаблон в шаблоне, мы можем использовать остальной функционал регулярок внутри группы. Например, если нам нужно засунуть класс внутрь группы – мы можем это сделать:
Мы можем даже засунуть группу в группу:
Но с этим приемом нужно быть аккуратными – позже вы узнаете, что каждая группа имеет свой порядковый номер, и он будет важен. Порядковый номер присваивается тогда, когда алгоритм натыкается на открывающую скобку, и при множественных вложенных скобках вы можете быстро запутаться – будьте аккуратны (а если это все же необходимо – рекомендуем дебажить регулярку через regex101, там каждая группа подсвечивается своим цветом).
Поиск с учетом контекста
Если вам нужно найти совпадение конкретно в начале или в конце строки – используйте якоря. Regexp предлагает 2 на выбор:
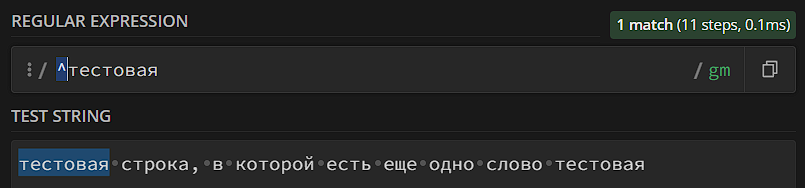
- Якорь начала строки – ^. Перед вхождением не должно быть других символов.
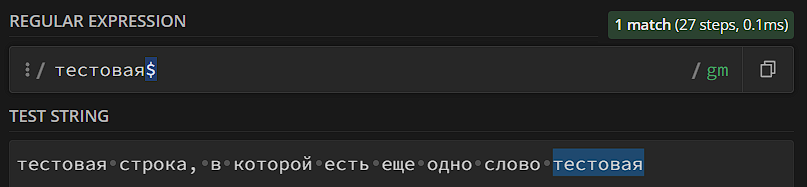
- Якорь конца строки – $. После вхождения не должно быть других символов.
Они могут использоваться вместе – в этом случае будет найдена конкретная совпадающая строка. Само по себе это не имеет большого смысла, но чуть ниже вы узнаете про квантификаторы, которые позволяют делать полезную конструкцию «.*» (любое количество любых символов) – с помощью якорей в этом случае можно делать поиск такого формата:
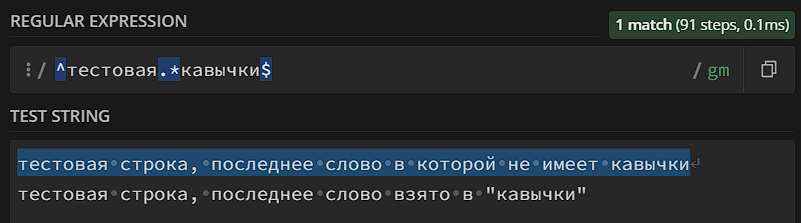
Еще один полезный якорь – \b, который указывает на границу слова. Если вы напишете \b404\b – совпадениями будут только те вхождения, в которых «404» окружено пробельными символами. \B работает обратным образом.
Второй полезный инструмент – это lookaround. Наиболее полезен он при замене/подстановке, но текст с его помощью искать тоже удобно. Lookaround позволяет указать, какие символы должны/не должны стоять до/после основного шаблона, чтобы это можно было считать совпадением. Lookaround бывает двух видов – lookahead (проверить после) и lookbehind (проверить до), каждый из этих видов бывает позитивным (что-то должно быть) или негативным (что-то должно отсутствовать). Как все это выглядит на практике:
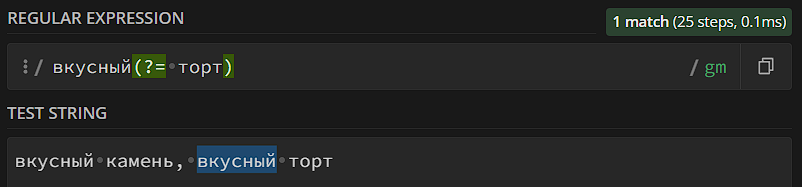
- Positive lookahead. Проверяет, что после шаблона есть определенная последовательность, форма: шаблон(?=проверка)
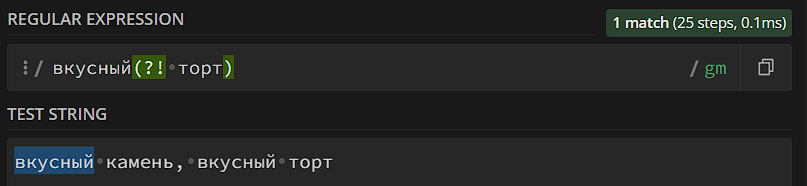
- Negative lookahead. Проверяет, что после шаблона отсутствует конкретная последовательность.
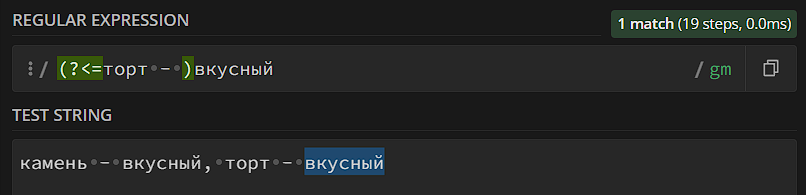
- Positive lookbehind. Проверяет наличие последовательности до основного шаблона.
- Negative lookbehind. Проверяет отсутствие последовательности до основного шаблона.
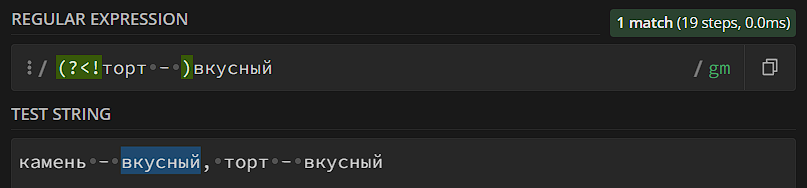
Механизм – простой, основная проблема – запомнить, как lookaround пишется в шаблоне. Он всегда находится в скобках и всегда начинается с «?», если нужно проверить что-то до фразы – ставим «<». Далее ставим «=», если это – позитивная проверка; для негативной проверки ставим «!». Lookbehind пишем слева от шаблона, lookahead – справа от шаблона (то есть с той стороны, в которой ищем).
Уровень Middle: квантифицируем, усложняем запросы
Квантификаторы
Итак, пришло время заметить слона в комнате, которого мы сознательно игнорировали: квантификаторы, инструмент, который делает регулярные выражения такими сложными и такими мощными. Все довольно просто, квантификатор обозначает число раз, которое может повториться шаблон или его часть. Квантификаторы можно ставить: после символа – символ должен повториться указанное число раз; после [класса] – любой из символов класса должен повториться указанное число раз; после \меты – то же, что и с классом; после (группы) – группа должна повториться указанное число раз.
Квантификатор обозначается либо мета-символом, либо фигурными скобками, в которых указано число повторений:
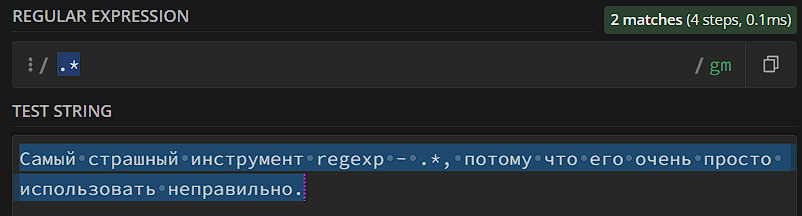
- Мета-символ «*». Паттерн может повториться любое количество раз, от 0 до бесконечности.
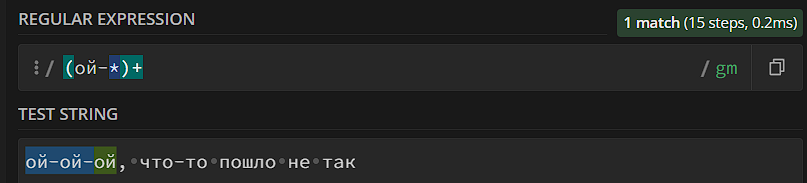
- Мета-символ «+». Паттерн должен повториться 1 или больше раз.
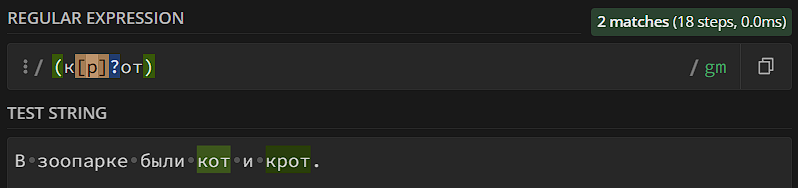
- Мета-символ «?». Паттерн должен повториться либо 0, либо 1 раз.
- Диапазон {n, m}. Паттерн должен повториться от n до m раз включительно.
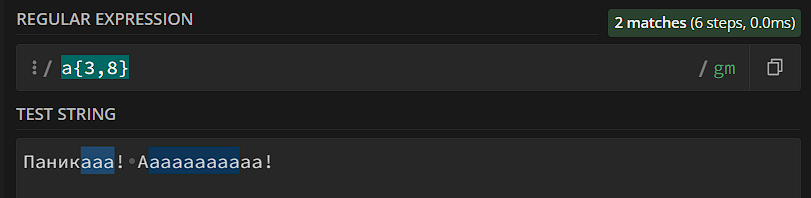
- Диапазон {n,}. Паттерн должен повториться как минимум n раз, максимальный предел не установлен.
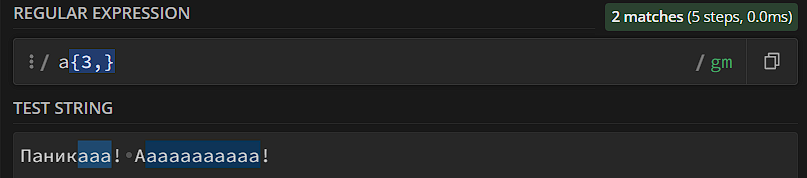
- Диапазон {n}. Паттерн должен повториться конкретное число раз.
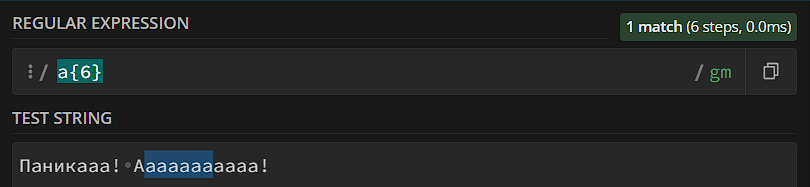
Номера групп, замена и подстановка
Теперь вы знаете всю базу, необходимую для построения регулярок средней сложности для поиска вхождений в тексте. Но regexp как технология умеет не только искать – в него встроена функция замены одного текста на другой по шаблону (конкретную реализацию этой функции ищите в гайдах к своему ЯП/окружению). Для того, чтобы протестировать указанные в этом разделе регулярки с помощью regex101.com, вам нужно перейти в «режим замены» – в левой колонке найдите раздел «FUNCTION», в нем нажмите на «Substitution». В центральном блоке появятся новые окна:
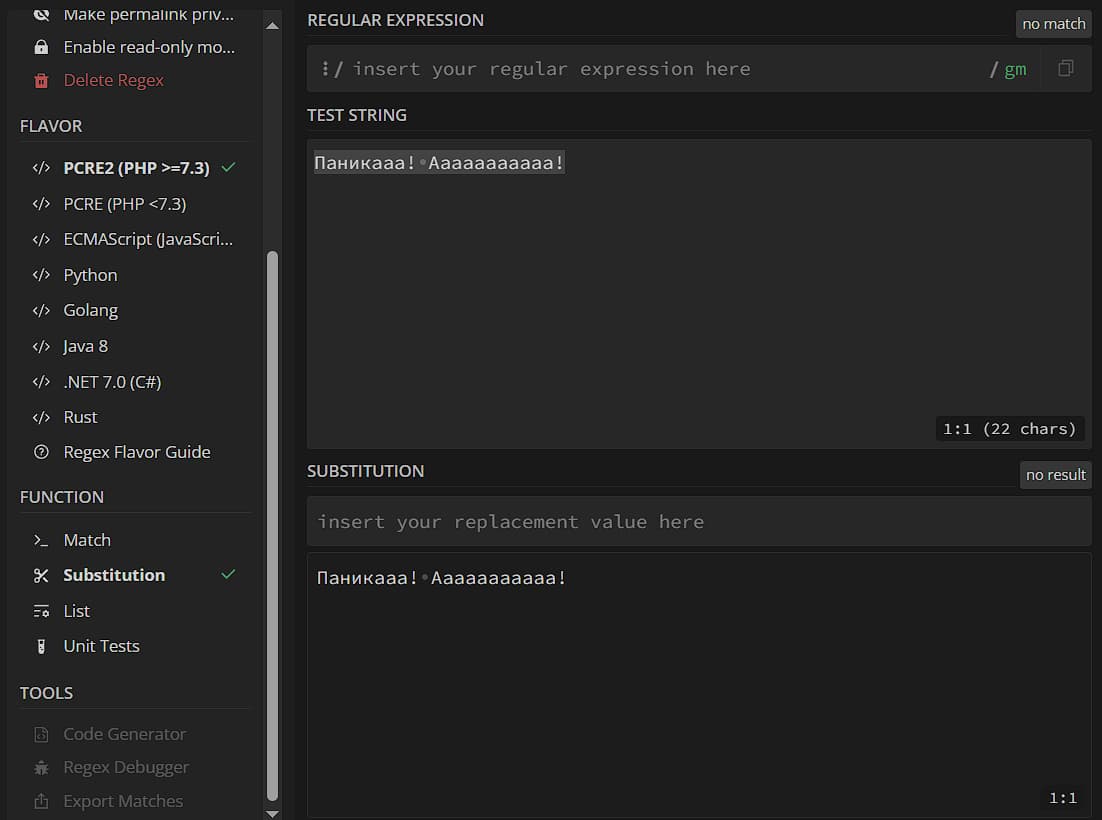
Сверху – регулярка и входящий текст, снизу – паттерн замены и получившийся текст. На скриншоте выше нет ни регулярки, ни паттерна замены, поэтому входящий текст равен получившемуся.
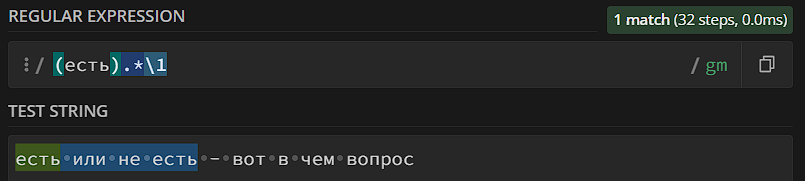
Итак, начнем с групп. Про их функции в плане поиска текста мы уже рассказывали, но у них есть еще одна функция: каждая группа, которую вы описываете, получает свой порядковый номер, начиная с 1. Например, в регулярном выражении «(Мама)(мыла)(раму)» группа (Мама) получает порядковый номер 1, (мыла) – порядковый номер 2, (раму) – порядковый номер 3. Группа с порядковым номером 0, кстати, тоже есть – ей соответствует все регулярное выражение. Так вот, мы можем ссылаться на группы с помощью мета-последовательности \1, \2, \3 и так далее:
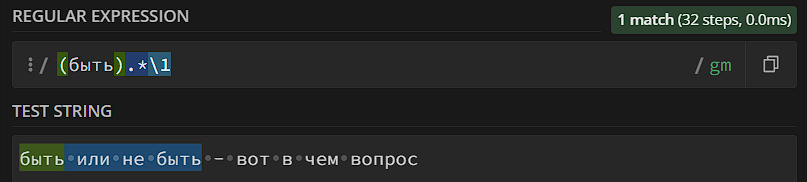
Это – довольно удобно, если у нас в регулярном выражении есть какой-то паттерн, который мы используем несколько раз – нам нужно изменить паттерн только в исходной группе, и во всех ссылках он тоже изменится:
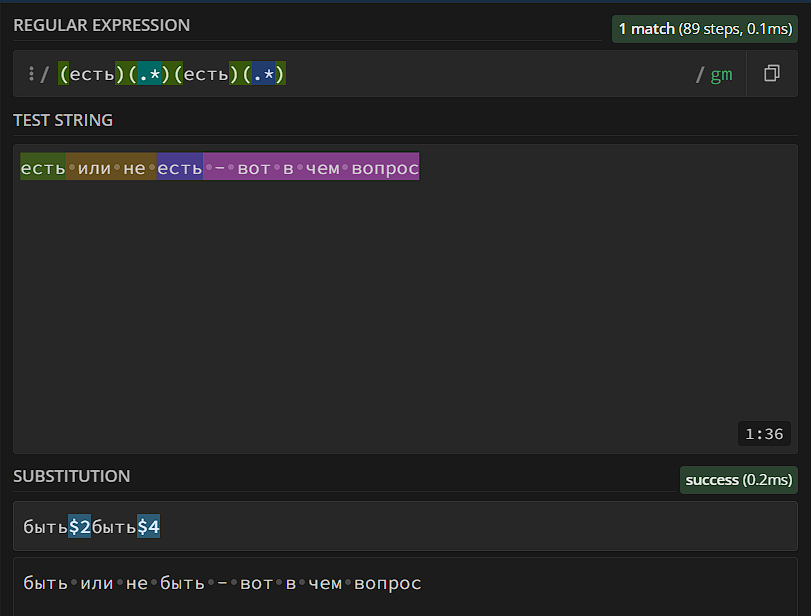
Что же касается замены – для этого используется специальный знак $, который по аналогии с \1, \2, \3… показывает, какие группы нам нужно вставлять. Самый простой способ замены заключается в том, что мы разбиваем вхождение на группы, после чего в замене пишем те части, которые должны остаться, а остальные – переписываем.
Уровень Senior: настраиваем поиск под окружение и обстоятельства
Здесь мы расскажем про нюансы, которые могут пригодиться вам в работе. Нюансы – специфичные и нужны далеко не всем, поэтому мы пройдемся по ним вкратце, хотите узнать больше – смотрите cheatsheet или документацию.
Ленивые, жадные и сверхжадные квантификаторы
Если в тексте есть несколько возможных совпадений, квантификатор сталкивается с дилеммой: что считать совпадением, самый длинный вариант или самый короткий вариант? Например, мы хотим найти все теги HTML в тексте, для чего пишем регулярное выражение «\<.*\>» – мы хотим найти любой текст, окруженный знаками < и >. Как только мы пытаемся использовать регулярку – все ломается:
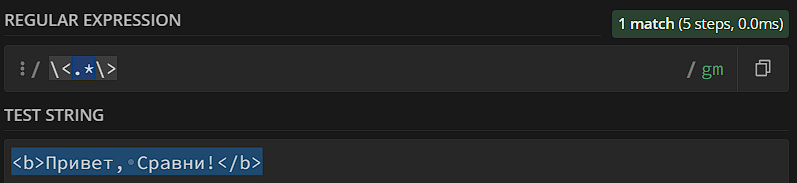
Мы хотели получить «<b>» и «</b>», а получили вообще всю строку – что тоже логично, ведь строка начинается с «<», заканчивается «>» и имеет какой-то там текст внутри. Это все – потому, что по умолчанию regexp использует жадные квантификаторы – те, которые пытаются захватить максимальный кусок. Если поставить после квантификатора знак «?», он станет ленивым – то есть постарается захватывать минимальные участки:
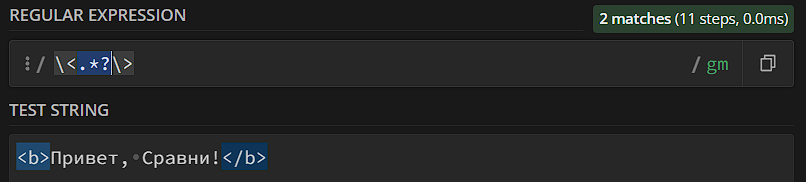
Есть еще сверхжадный режим – активируется знаком «+» после квантификатора. Работает почти так же, как и жадный (хотя иногда выдает даже более качественный результат за счет отсечения нежелательных совпадений), главное преимущество – ест намного меньше ресурсов сервера, потому что не позволяет алгоритму проходить по тексту рекурсивно, если частичное совпадение уже найдено.
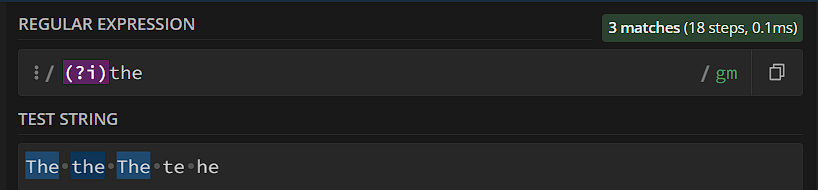
Флаги и модификаторы
«Глобальные настройки» regexp можно менять прямо в регулярном выражении – выключить чувствительность к регистру, переключиться между single line/multiline, игнорировать все пробелы, включить ленивую квантификацию для всего регулярного выражения и так далее. Делается это конструкцией (?флаг), например – выключить чувствительность к регистру:
Полный список флагов/модификаторов смотрите в cheatsheet и документации к своей реализации regexp.
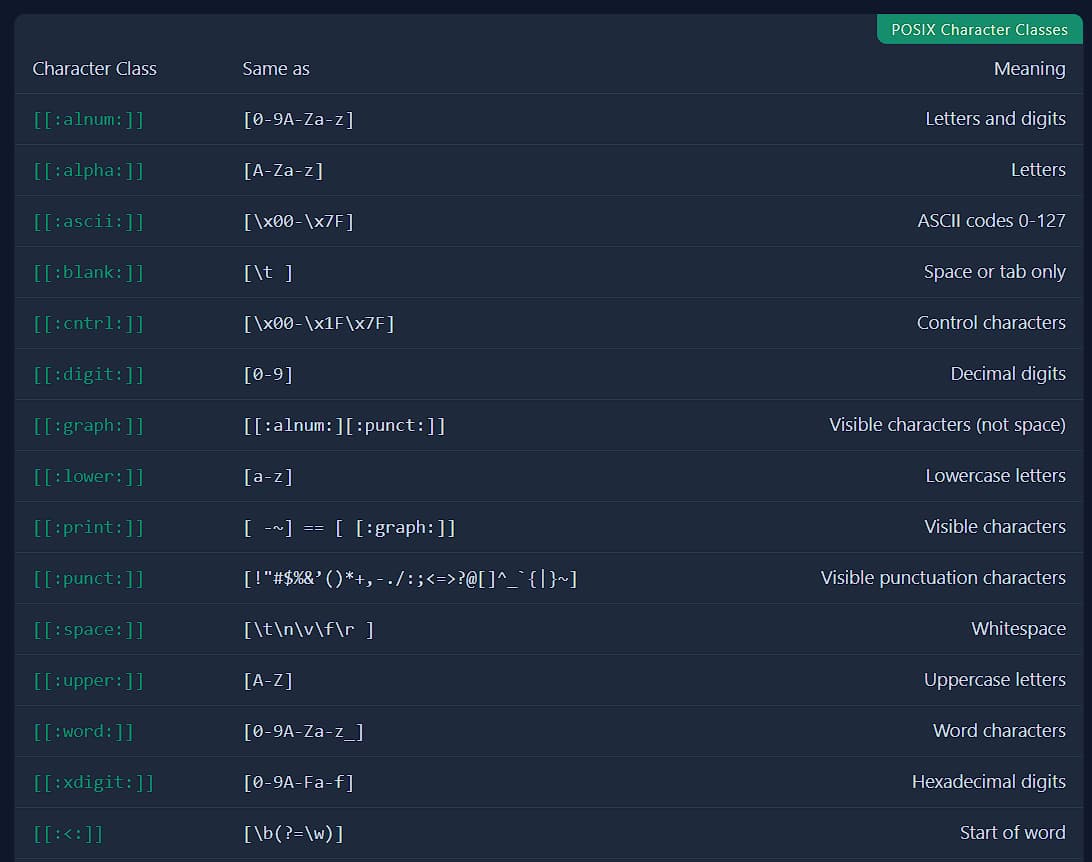
Особые группы и команды
Regexp – это универсальный язык, но конкретные его реализации могут добавлять что-нибудь новое. Например в Ubuntu (и всех POSIX-языках) есть ряд своих заготовленных мета-последовательностей:
А в ЯП вообще существуют классы, имеющие свой собственный функционал – регулярки можно создавать как объекты и вызывать у них методы. Все это, опять же, смотрите в документации к своему языку.
Примеры регулярок с разбором
Разберем 5 популярных регулярок, которые вы можете использовать хоть прямо сейчас.
Юзернейм
Регулярка: ^[a-zA-Z0-9_-]{3, 16}$
Разбор:
- В типичном юзернейме позволяется использовать латинские буквы, цифры, дефис и знак подчеркивания: ^[a-zA-Z0-9_-]{3, 16}$
- Мы хотим, чтобы длина юзернейма была ограничена – от 3 до 16 символов: ^[a-zA-Z0-9_-]{3, 16}$
- Обычно юзернейм передается отдельным string, и мы хотим убедиться, что ничего лишнего в строку не попало: ^[a-zA-Z0-9_-]{3, 16}$
Пароль
Регулярка: ^[a-zA-Z0-9_-]{6,18}$
Если вы хотите разрешить дополнительные спецсимволы в пароле – просто допишите их в класс.
Разбор:
- Сначала мы определяем список символов, которые можно использовать в пароле: ^[a-zA-Z0-9_-]{6,18}$
- Затем мы указываем, сколько символов (минимально/максимально) должно быть в пароле: ^[a-zA-Z0-9_-]{6,18}$
- Наконец, мы проверяем, что в строку не попало ничего лишнего: ^[a-zA-Z0-9_-]{6,18}$
Шестнадцатеричный цвет
Регулярка: ^#?([a-f0-9]{6}|[a-f0-9]{3})$
Разбор:
- Шестнадцатеричный цвет записывается либо в полном формате (#fff000), либо в сокращенном (#fff). Решетка перед номером цвета может быть, а может и отсутствовать – сначала займемся ей: ^#?([a-f0-9]{6}|[a-f0-9]{3})$
- Теперь открываем группу, в которой через «или» (знак |) будут описаны оба варианта. Допустимые символы – от 0 до 9, от a до f. Полная запись цвета: ^#?([a-f0-9]{6}|[a-f0-9]{3})$
- Короткая запись цвета: ^#?([a-f0-9]{6}|[a-f0-9]{3})$
- Проверяем, что в строке больше ничего нет (если это необходимо): ^#?([a-f0-9]{6}|[a-f0-9]{3})$
Проверка адреса электронной почты
Сразу оговоримся – есть большое число регулярок для проверки валидности почты, все зависит от того, с какой почтой сервис чаще работает. Мы приводим общепринятый вариант, не учитывающий странные редкие адреса. Итак, регулярка: ([a-z0-9_.-]+)@\1\.([a-z.]{2,6})
Разбор:
- Типичный адрес почты – имя@домен.домен_верхнего_уровня. Для начала создадим 3 группы (для имени, домена и домена верхнего уровня) и добавим «собаку» и точку: ([a-z0-9_.-]+)@([a-z0-9_.-]+)\.([a-z.]{2,6})
- Теперь зададим правила для имени – в нем могут содержаться буквы, цифры, дефис, знак нижнего подчеркивания и точка: ([a-z0-9_.-]+)@([a-z0-9_.-]+)\.([a-z.]{2,6})
- Тот же набор правил используется для домена, поэтому нам не обязательно писать его заново – удаляем вторую группу, ставим вместо нее ссылку на первую группу: ([a-z0-9_.-]+)@\1\.([a-z.]{2,6})
- Наконец, задаем правила для домена верхнего уровня – буквы или точка, от 2 до 6 символов: ([a-z0-9_.-]+)@\1\.([a-z.]{2,6})
Проверка URL на валидность
Регулярка: (https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([\/\w.-]*)*\/?
Разбор:
- Адрес может быть указан либо с указанием протокола в начале, либо без указания; кроме того, протокол может быть как http, так и https. Сначала разберемся с протоколом: (https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([\/\w.-]*)*\/?
- Теперь разберемся с указанием протокола вообще: (https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([\/\w.-]*)*\/?
- URL состоит из двух частей: адрес сервера и адрес страницы на сервере, разделяются они первым слэшем в адресе (http:// мы не учитываем) – все последующие слэши относятся к адресу страницы. Начнем с адреса сервера – он может состоять из любых цифр, букв или дефиса. Если сайт расположен на поддомене – где-то в адресе сервера будет точка: (https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([\/\w.-]*)*\/?
- Любой адрес сервера заканчивается точкой, после которой идет домен высшего уровня – зададим это правило: (https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([\/\w.-]*)*\/?
- Наконец, в адресе страницы могут встречаться любые буквы/цифры, точки, дефисы и слэши. А могут и не встречаться. Адрес страницы может иметь слэш в конце – а может и не иметь (но если он есть, то он обязательно должен быть один). Зададим все эти правила: (https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([\/\w.-]*)*\/?
Где брать референсы, cheatsheet и дополнительную информацию?
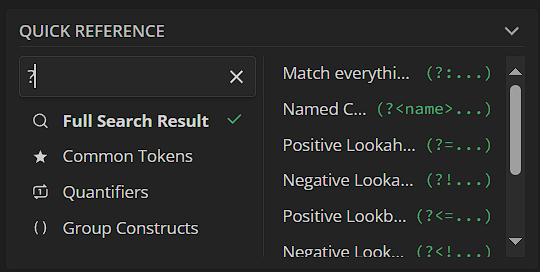
Cheatsheet можно найти в интернете, как пример – тут. Если хотите более детальные пояснения по каждой команде – их можно найти на regex101.com, в нижнем правом блоке, «Quick Reference» (выберите All Tokens и найдите нужный через поиск):
Примеры хороших регулярок тоже можно найти на regex101.com – в самом левом меню выберите «Community Patterns» и найдите нужный. Или вы можете найти нужную регулярку в поисковике, после чего – сходить на regex101 и проверить ее работоспособность.
Собственно, дополнительную информацию тоже лучше искать в Гугле, если у вас нет проблем с английским – вы быстрой найдете то, что вам нужно. Если же вы работаете с конкретным языком программирования – в большинстве случаев у него есть класс regexp, и его работа хорошо описана в базовой документации – изучайте.