Оконные функции
Оконные функции – это функции, которые позволяют производить какие-либо вычисления в SELECT, вынося результат в отдельный столбец. «Оконными» их называют потому, что такая функция проходится по всей таблице, выделяя для каждой строки «окно», в рамках которого происходят вычисления – различные функции ранжирования «уточняют» размер окна для каждой позиции. Ниже: как это работает, как выглядит синтаксис оконных функций, какие типы бывают и как использование оконных функций выглядит на практике.
Оконные функции – что это и чем отличается от агрегирующих функций
Предположим, у вас есть база учеников, для каждого ученика в этой базе хранятся предметы, которые ученик проходит, и оценки, которые ученик получил по предмету. Вам нужно составить аналитический запрос, который позволит узнать среднюю оценку ученика. Простой способ – использовать агрегатную функцию AVG вместе с GROUP BY:
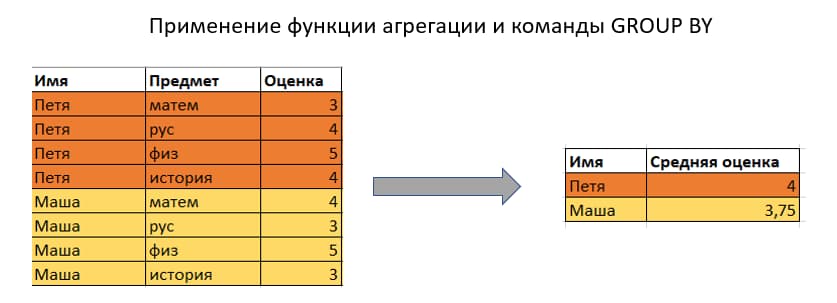
Вроде как результат получен, но есть проблема – агрегатная функция «съела» набор строк, убрав все предметы – мы получили только учеников и среднюю оценку. Если мы хотим сделать что-нибудь еще с информацией из базы – нам нужно заново делать запрос.
Оконные функции как раз эту проблему и решают – когда мы отправляем ее серверу, он выполняет вычисления, которые мы ему указали, после чего в неизменном виде возвращает исходные данные, а результаты вычисления появляются в новом столбце:
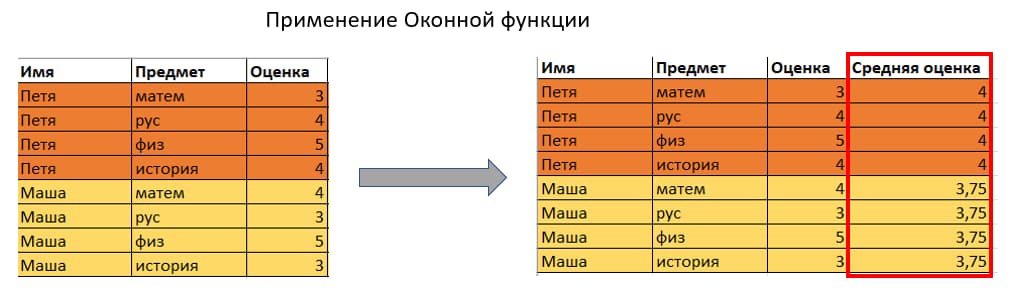
Конкретно в этом примере со средней оценкой такой объем информации может быть избыточным, но если мы хотим, чтобы сервер возвращал ранг, или планируем еще что-то делать с присланными данными – оконные функции будут более полезными, чем агрегирующие (и не будут создавать такую нагрузку на сервер).
Синтаксис
Когда вы пишете какую-либо аналитическую функцию, вам нужно написать и саму оконную функцию, и SELECT, в котором эта оконная функция будет применяться (в одном SELECT может быть несколько таких конструкций, к слову). Сами оконные функции выглядят так:
<функция_для_расчетов>(столбец) OVER ([PARTITION BY столбец] [ORDER BY столбец [ASC | DESC]] [ROWS | RANGE …]) as 'столбец'
Квадратные скобки обозначают необязательные параметры – то есть можно вообще написать SUM(salary) OVER () as ‘sum’, и это будет работать. Разберем каждую команду в отдельности:
- <функция_для_расчетов>(столбец) – агрегатная функция, функция смещения или любая другая, которая будем использоваться для расчетов значений нового столбца. О классах этих оконных функций мы расскажем ниже. В качестве аргумента нужно передать столбец, данные из которого будут использоваться в расчетах.
- OVER – ключевое слово, по которому база понимает, что мы используем оконную функцию.
- [PARTITION BY столбец] – то, что делает оконную функцию оконной. С помощью PARTITION BY мы указываем столбец, по которому таблица будет разделена на фреймы (окна). Например, если в таблице учеников мы укажем PARTITION BY Имя – таблица будет разделена на 2 фрейма, «Петя» и «Маша», для каждого фрейма вычисления базовой функции будут производиться отдельно.
- [ORDER BY столбец [ASC | DESC]] – указывает, в каком порядке будут выводиться строки, основой будут данные столбца. Можно просто указать порядок – возрастающий или убывающий.
- [ROWS | RANGE …] – с помощью оконных функций можно сузить выборку для расчетов физически или логически – вы, например, можете возвращать только предыдущие строки в вычисления или для каждого вычисления учитывать предыдущую строку. ROWS указывает на конкретный диапазон строк (берем со 2-й по 7-ю), RANGE указывает на логический диапазон строк (берем текущую и две предыдущие). Для ROWS и RANGE можно задавать множество уточняющих операторов (вроде UNBOUNDED PRECEDING, CURRENT ROW, BETWEEN AND и других), уточняйте набор операторов в документации к вашей реализации SQL.
Вторая «часть» синтаксиса оконной функции – это ее позиция в запросе:
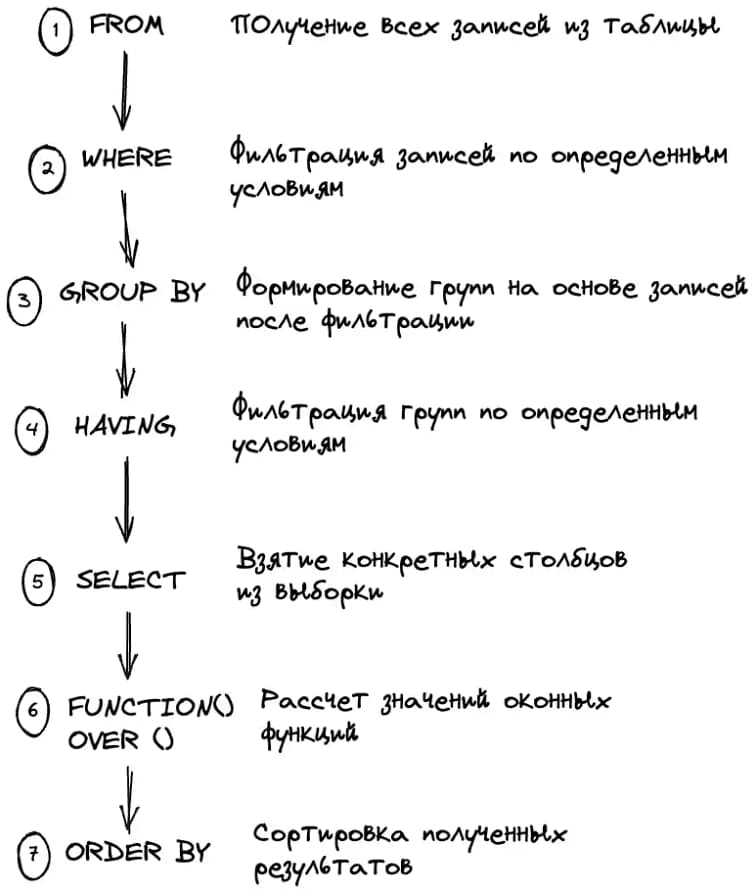
- В первую очередь обрабатывается FROM, который указывает, откуда и что именно брать.
- Затем данные отсеиваются по условию WHERE.
- Если нужно – используется группировка, условия которой прописаны в GROUP BY.
- Группы тоже можно фильтровать – для этого используется HAVING.
- Если нужна не вся база, а конкретные столбцы – выбираем их через SELECT.
- Наконец, используем оконную функцию через OVER().
- После того, как функция отработала, можно дополнительно отсортировать результат через ORDER BY.
Виды оконных функций + примеры
Агрегатные
Стандартные агрегатные функции, только в этом случае к ним добавляется OVER() и дополнительные условия при необходимости. Основные использующиеся – SUM (сумма), COUNT (количество), MAX (максимальное), MIN (минимальное), AVG (среднее). Агрегатная оконная функция выглядит так:
SELECT
department,
employee_id,
salary,
hire_date,
SUM(salary) OVER (PARTITION BY department ORDER BY hire_date) AS cumulative_salary
FROM
employees;
Здесь мы суммируем зарплату, разбивая ее по отделам и упорядочивая по дате найма каждого сотрудника, данные отображаются в новом столбце «cumulative_salary».
Ранжирующие
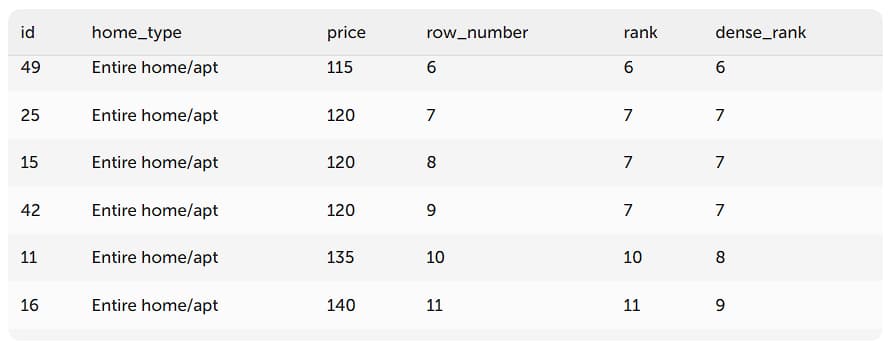
Эти функции ранжируют данные в указанном столбце, то есть присваивают им какой-то номер. Ранжирующие функции всегда используются вместе с [GROUP BY столбец], потому что вы должны указать принцип, по которому данные будут ранжироваться. Основных ранжирующих функций – 3: ROW_NUMBER, RANK, DENSE_RANK. ROW_NUMBER() просто присваивает каждой строке уникальный номер – ее удобно использовать как вложенную функцию для нумерации.
С RANK все немного интереснее – эта функция присваивает ранг, основываясь на ORDER BY:
SELECT
employee_id,
first_name,
last_name,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank
FROM
employees;
Этот запрос выведет все зарплаты от самой большой к самой маленькой, в отдельном столбце будет выведен ранг – 1 получит самая большая зарплата, 2 получит следующая и так далее. Если, например, 2 и 3 место будут иметь одинаковую зарплату – они получат ранг «2», а ранг «3» будет пропущен. DENSE_RANK работает немного иначе – ранг «3» не будет пропущен.
Функции смещения
Наконец, третий тип – оконные функции смещения. Как понятно из названия, они возвращают результат, смещенный относительно целевой строки. Сами по себе они не то чтобы очень полезны, но их часто используют во вложенных и составных запросах. Основных функций смещения – 4: FIRST_VALUE, LAST_VALUE, LAG, LEAD. С FIRST_VALUE и LAST_VALUE все довольно просто – они возвращают первое и последнее значение в столбце (или фрейме) соответственно. LEAD и LAG возвращают значение со смещением – LEAD возвращает значение после целевого, LAG возвращает значение до целевого. Обе функции принимают 3 параметра: 1) столбец, с которым будем работать; 2) смещение, по умолчанию – 1; 3) значение, которое нужно вернуть, если результатом будет NULL. Пример запроса:
SELECT
employee_id,
first_name,
last_name,
salary,
LEAD(salary, 2, -1) OVER (ORDER BY hire_date) AS next_salary
FROM
employees;
В данном случае для каждой строки в столбце salary мы получаем значение, которое будет через 2 строки (смещение – 2), а если в результате смещения мы получим NULL – вместо него вернется -1.
Кратко о главном
- Оконные функции – это функции, которые позволяют разбить таблицу на фреймы (окна) и работать с каждым отдельно.
- Результат работы оконной функции – новый столбец.
- Оконные функции можно довольно тонко настраивать по фрейму, сортировке и выборке (жесткой или логической).
- Типы оконных функций – агрегирующие, ранжирующие, смещения.
- Конкретный синтаксис оконных функций для вашего сервера может отличаться от базового, проверяйте документацию.