Машинное обучение: как устроено внутри и на что способно
Машинное обучение со стороны выглядит как магия, при условии, что вы магом не являетесь: про ML все говорят, оно везде есть, но вы его не видите. Аура загадочности подпитывается и писателями-фантастами – те уже давно придумали концепцию разумных машин, порабощающих человечество, и технология machine learning выглядит и звучит так, будто будущее с умными роботами вот-вот наступит. Не забываем и про деньги – программисты, которые освоили алгоритмы машинного обучения (а еще вышмат и статистику), зарабатывают если и не 300кк в наносекунду, то близко к этому. Если все это сподвигло вас поискать информацию о том, как machine learning работает, то вы наткнетесь на один из двух типов обучающих материалов: либо очень длинные и очень сложные формулы, либо хвалебная ода вообще без какой-то конкретики. Наш материал призван заполнить разрыв между этими двумя типами гайдов: ниже вы без формул, но с конкретикой познакомитесь с разными типами машинного обучения (да, их много), а также узнаете, где его применяют и по какой логике его разрабатывают. Нет, этот материал не сделает из вас профессионального разработчика глубоких нейронных сетей, но он даст вам базовое понимание ML, с которым вы сможете осознанно «копать» дальше.
Машинное обучение – что это такое
Еще в школе, при изучении математики, вы решали всякие задачки, у которых была одинаковая структура: «Дано», «Решение», «Ответ». Эти 3 блока следуют друг за другом по цепочке: вы изучаете данные, которые вам предоставили для решения задачи (единственное, что у вас изначально есть) -> вы разрабатываете некоторое пошаговое решение (алгоритм) -> вы приходите к результирующему набору данных (ответу). Если представить, что учитель математики дал вам 1 000 заданий на дом на одну и ту же тему, то решать их самостоятельно было бы затруднительно – лучше научиться программировать и доверить решение компьютеру. Ваша программа будет выглядеть так: (произвольные данные определенного формата на входе) -> (ваш алгоритм, который решает задачи определенного вида) -> (ответ). Все, вам нужно 1 раз написать алгоритм – и вы сможете решить хоть 1 000 задач, хоть 1 000 000 задач. Так работает классическое программирование – вы анализируете формат входных данных, разрабатываете алгоритм для преобразования этих данных нужным вам образом, получаете ответ.
Итак, задачку «У Пети было 3 яблока, у Васи – 4. Сколько яблок было в сумме?» вы решили классическим программированием – просуммировали и выдали ответ. Можно подставлять любые числа, алгоритм нахождения суммы все сделает. А теперь давайте представим, что вам на дом задали более сложную задачку:
- Дано: сегодня Петя купил 2 новых телевизора, Вася – 5 новых квартир. Ответ: ключевая ставка ЦБ РФ = 4%.
- Дано: сегодня Петя купил 2 буханки хлеба, Вася заваривает чайный пакетик второй раз. Ответ: ключевая ставка ЦБ РФ = ???.
Вам нужно найти КС из второго пункта задачи. И тут у вас закономерно возникает вопрос: а что вообще происходит? Вас такому не учили, классическая парадигма (набор устоявшихся принципов) школьного обучения гласит, что есть входные данные и гарантированно есть алгоритм решения – осталось только его придумать. Тут же все иначе: у вас есть ответ к схожему случаю и набор входных данных, но не только нет идей по алгоритму, но и нет ответа на вопрос: «А есть ли алгоритм вообще?». Здесь вам и помогут алгоритмы машинного обучения. Их суть – в том, чтобы получить много данных и найти между ними взаимосвязь. У вас всегда есть входные данные, иногда есть данные на выходе, и вам нужно найти связи во всех этих данных, причем так, чтобы ваш искусственный интеллект в будущем мог в дальнейшем сам по входным данным прогнозировать результат – это называется регрессией. В задачке выше вы нашли еще 100 000 таких вот решенных примеров, научили алгоритм искать цену предметов из задачи и ключевую ставку на сегодня, после чего ИИ выдал вам ответ: 25%. Вы сдали задачку математику и получили 5 баллов за работу. Кстати, почему 25% – верный ответ, вы так и не узнали.
А теперь давайте познакомимся с машинным обучением более научным языком. Машинное обучение – это ряд методов из сферы искусственного интеллекта, которые решают поставленную задачу путем поиска закономерностей в схожих решенных задачах. Машинное обучение – один из видов искусственного интеллекта, но не каждый искусственный интеллект является машинным обучением:
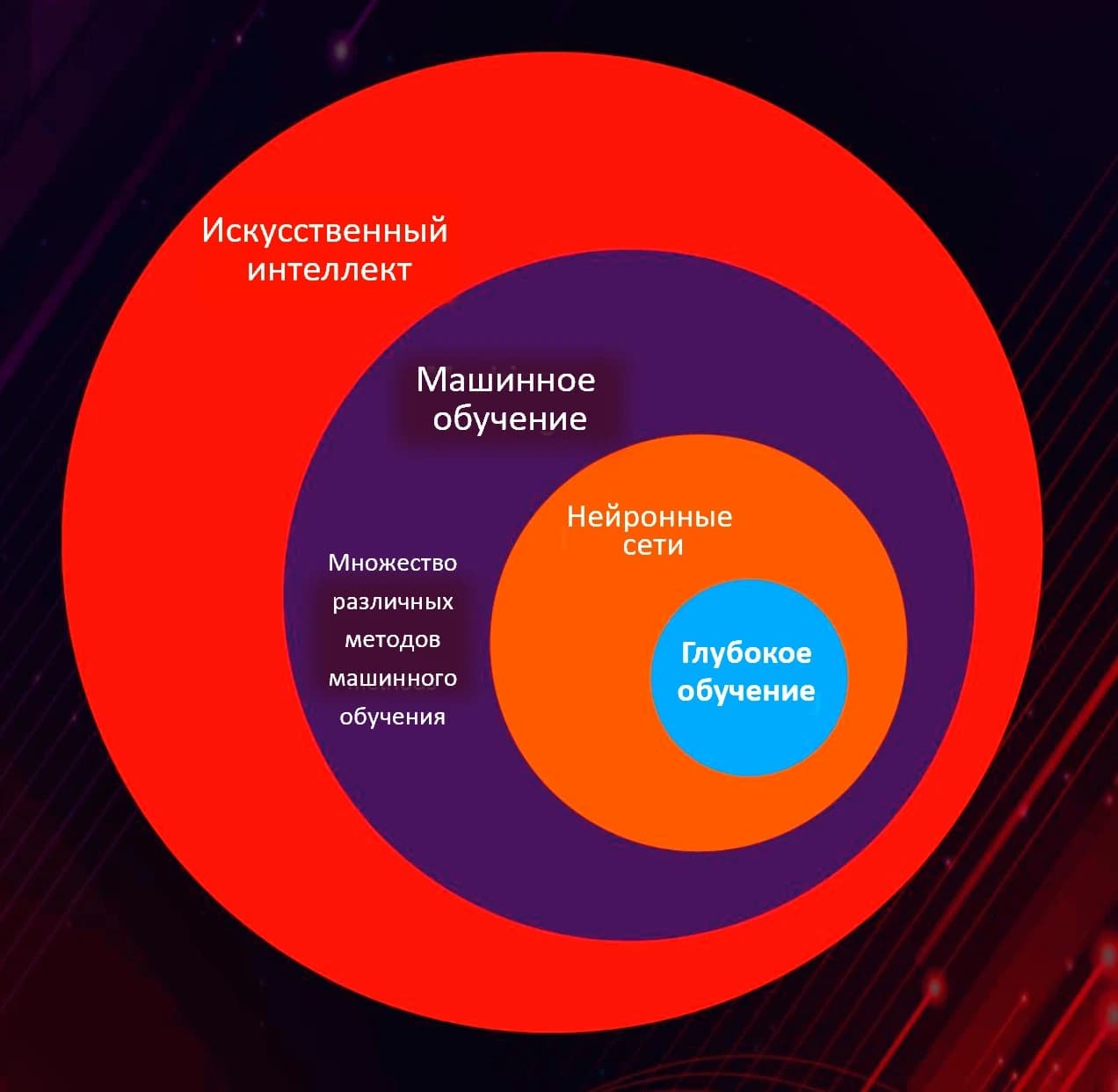
- Искусственный интеллект. Любой алгоритм, который может принимать решения. «Если таймер в 30 минут истек, то выключить плиту» – тоже искусственный интеллект.
- Машинное обучение. Подвид искусственного интеллекта, который может обучаться самостоятельно, то есть искать закономерности.
- Нейронные сети и глубокое обучение. Подвиды машинного обучения (сейчас между НС и ГО большой разницы нет), которые используют для анализа данных логику «нейронов».
Детально различия в методах машинного обучения мы разберем в следующем разделе.
Напоследок разберем 3 составляющие любой системы машинного обучения, без которых построение модели машинного обучения в принципе невозможно:
- Данные. Отвечает на вопрос: Что мы изучаем? Без данных модель машинного обучения построить невозможно, потому что ей будет не на чем учиться.
- Признаки. Отвечает на вопрос: На что именно мы обращаем внимание? Например, мы даем нейронке фото котика. На что ей смотреть – на цвет пикселей, на геометрические фигуры, на перепады цветов в соседних блоках пикселей? Именно мы задаем те параметры входных данных, на которые будет смотреть нейронка.
- Алгоритм. Отвечает на вопрос: Как мы обрабатываем данные? Машинный перевод можно создать практически всеми видами машинного обучения, но одни алгоритмы будут работать медленно, другие – быстро. Здесь и нужно знание вышмата/статистики, с ним вы будете знать, как именно быстрее всего обработать конкретный массив данных и какие алгоритмы будут выдавать ответ «на лету». Если вы только начинаете разбираться в нейронных сетях, слишком сильно на алгоритмах не зацикливайтесь – выберите тот, который вам понравился, и пытайтесь его реализовать.
Итак, с общими для всех алгоритмов машинного обучения чертами мы разобрались, пора переходить к различиям – видам машинного обучения.
Виды машинного обучения и как оно устроено
Классическое обучение
Название говорит само за себя, эти принципы машинного обучения – самые простые, древние и изученные. Они делятся на 2 типа:
- С учителем. Есть живой человек (или другая нейронка, такое тоже случается), который обучает ИИ, то есть говорит, что правильно и что неправильно. Подходит для случаев, когда данные каким-то образом упорядочены.
- Без учителя. В данных нет порядка, поэтому даже если учитель есть, то ничего полезного он сделать не сможет, потому что непонятно, на что смотреть.
Чаще всего используются алгоритмы с учителем, потому что результат можно получить быстро, и он будет качественным. Алгоритмы без учителя – единственный вариант, когда нужно найти закономерности в хаотичных данных, но работают эли алгоритмы прямо очень медленно, поэтому к ним прибегают только в крайних случаях.
Обучение с учителем
В библиотеках машинного обучения можно встретить 2 вида алгоритмов с учителем:
- Классификация. Машине на вход подается ряд объектов, после чего машина учиться разделять эти объекты по категориям. Нужны размеченные данные и признаки, на которые нужно смотреть – второе задает учитель.
- Регрессия. То же, что и классификация, только мы ищем не принадлежность объекта к классу, а какое-то число. Учитель показывает, какие входные числа имеют значение, а ИИ пытается найти алгоритм, по которому можно предсказать следующее число в последовательности.
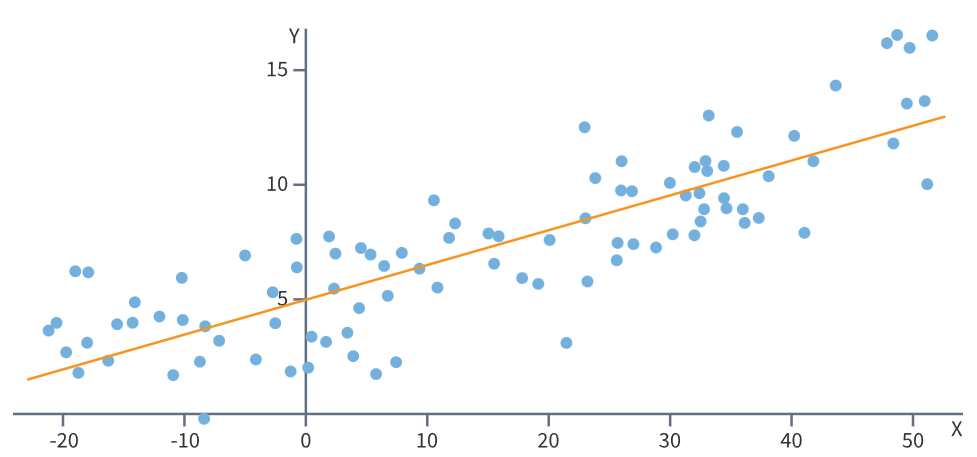
Регрессия создается математическими функциями – ИИ размещает на графике имеющиеся данные, ищет базовую линию и на ее основе пытается предсказать следующие значения с учетом возможных отклонений. Регрессия отлично работает в случаях, когда что-то происходит в зависимости от времени.
С классификацией все несколько более сложно, здесь применяются 2 алгоритма: дерево решений и метод опорных векторов. Дерево решений – это просто набор вопросов, на которые обычно можно ответить односложно:
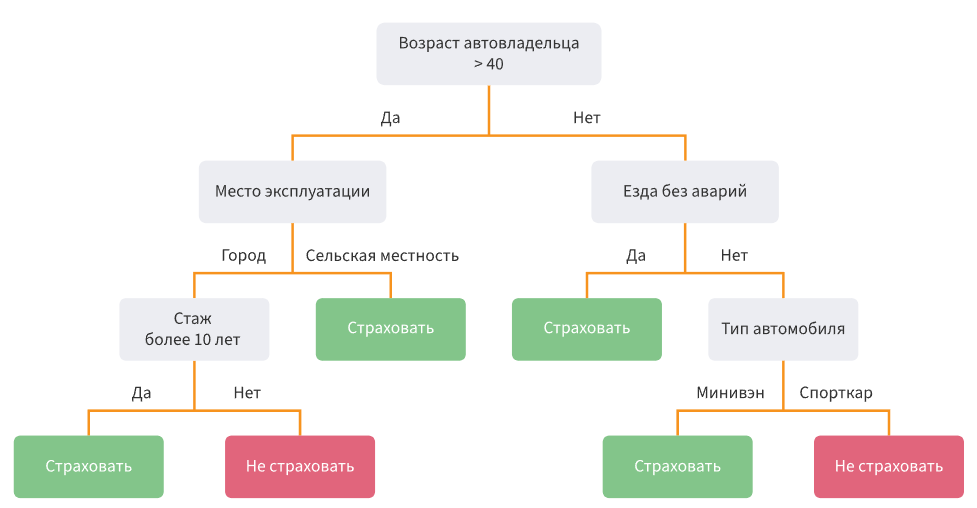
Да, если вы видели шутки про то, что ИИ – это просто большой набор «if … else …», то шутки пошли именно отсюда. Но не стоит недооценивать деревья решений – они часто используются в более серьезных видах машинного обучения, в ансамблях. А если мы добавим в дерево решений веса и научим алгоритм самостоятельно эти веса подбирать – уже получим что-то похожее на глубокое обучение.
Второй метод классификации – опорные векторы:
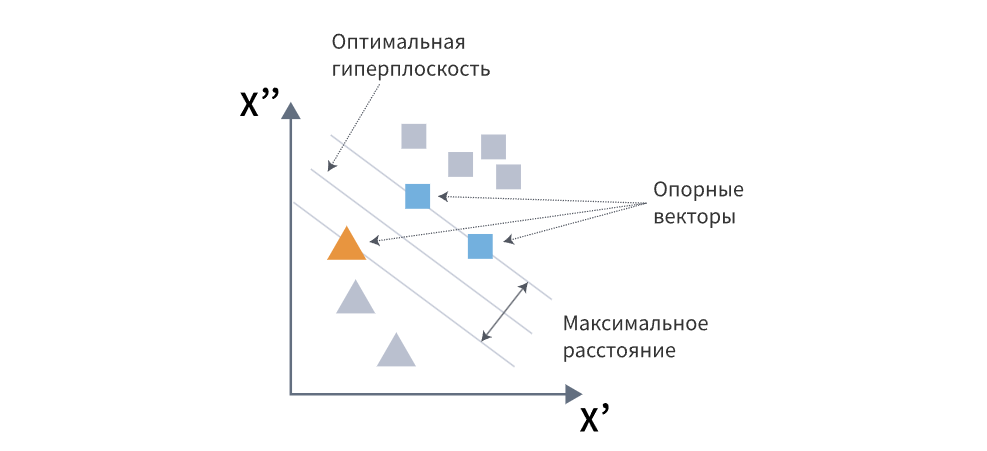
Здесь мы помещаем разные объекты на плоскости, используя признаки в качестве координат, и ищем такую комбинацию, при которой между группами объектов будет максимальное расстояние – в этом случае между группами будет максимальное различие, что и позволит нам доказать, что это – действительно разные группы.
Обучение без учителя
Здесь выделяют 3 основных подхода: кластеризация, уменьшение размерности, ассоциация.
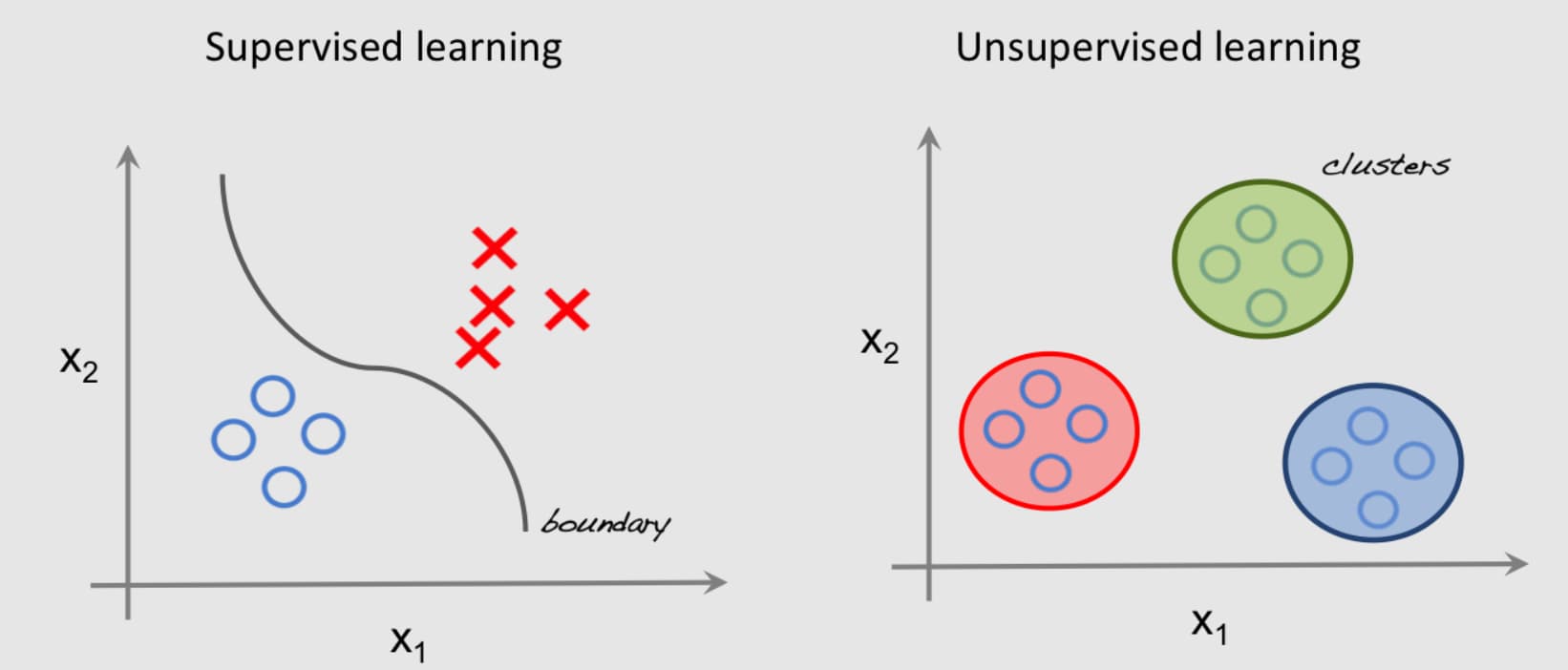
Чаще всего используют кластеризацию – ИИ ищет кластеры на графике (что-то похожее на опорные векторы, но сложнее). Уменьшение размерности и ассоциация съедают очень много ресурсов и не гарантируют хоть какой-нибудь результат, поэтому их используют крайне редко.
Обучение с подкреплением
Если вкратце, то в этом случае мы говорим искусственному интеллекту: «Я не дам тебе полный набор данных, но за правильное решение ты будешь получать печеньку». Затем мы выбрасываем его из самолета без парашюта на высоте в 10 км и смотрим, что он будет делать.
Есть 2 основных подхода: без модели или с моделью. Модель – это буквально модель «окружающего мира», в который попадает алгоритм машинного обучения. При наличии модели ML учится быстрее, поскольку знает, где находится. Например, такое обучение можно использовать для того, чтобы научить Пакмана избегать привидений в игре:

Но описать окружающий мир не всегда возможно – машины с автопилотом не могут загрузить себе в память всю Землю с расположением всех столбов и пешеходов:

В целом этот вид машинного обучения работает так: помещаем робота в среду; рассказываем ему, на какие вещи нужно смотреть; даем ему инструменты, с помощью которых он может самостоятельно принимать решения; наказываем его за плохие решения и поощряем за хорошие. К счастью, роботы не понимают концепцию денег, поэтому для поощрения достаточно дать ему очки, а для наказания – забрать. В итоге машина запоминает, какие действия в определенных ситуациях приносят ей больше очков, и старается воспроизводить эти действия как можно чаще. Только не задумывайтесь о сходстве такого робота с людьми – можете наткнуться на темные мысли.
Ансамблевые методы
Тут все просто и сложно одновременно. Ансамблевый метод – это когда мы берем несколько классических методов и применяем их одновременно. Есть 3 подхода:
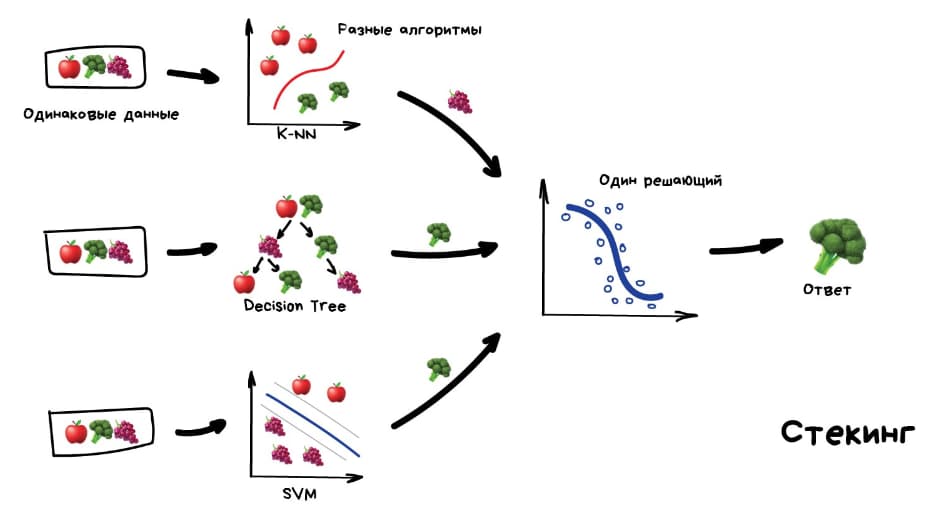
- Стэкинг. Мы прогоняем один набор данных через разные классические методы, после чего собираем результаты и прогоняем их через один результирующий метод.
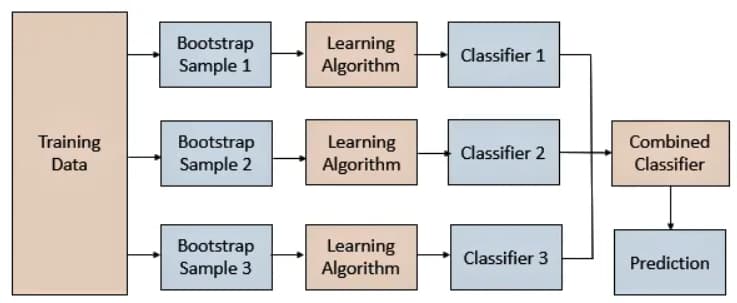
- Беггинг. Берем один алгоритм, прогоняем через него разные куски одного набора данных, в конце выводим среднее.
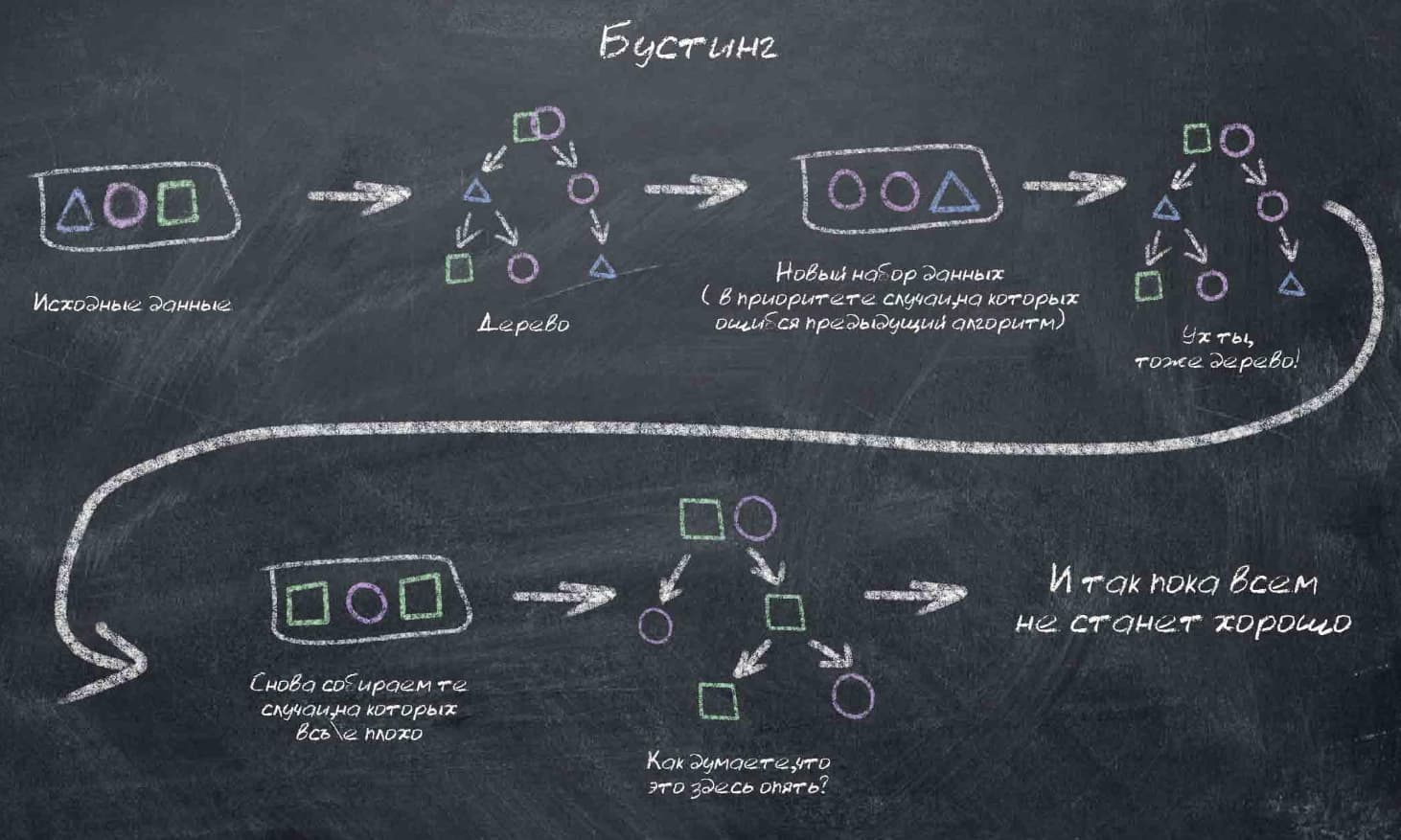
- Бустинг. Берем один алгоритм и один набор данных, прогоняем данные через алгоритм, отбираем те случаи, в которых алгоритм ошибся. Прогоняем через алгоритм ошибочные ответы, выбираем из новых ответов те, в которых ИИ опять ошибся. И так – пока не надоест или пока не закончатся неправильные ответы.
Интересно, что ансамблевые методы по эффективности не уступают нейросетям, при том что построены они на простых классических методах. Поскольку реализовать ансамблевый метод – проще, чем реализовать нейронку, при возможности вы должны отдавать предпочтение именно ансамблю.
Нейросети и глубокое обучение
Вот мы и добрались до методов глубокого обучения. Разделение между нейросетями и глубоким обучением существует, но с годами оно становится все слабее. И то, и то построено на принципе нейронов и связей:
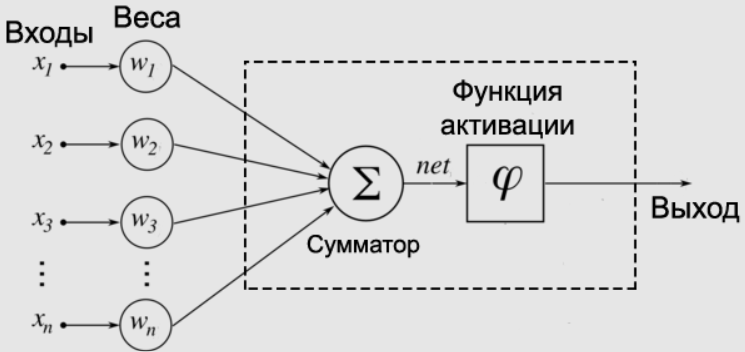
Нейрон – это не тот нейрон, который у нас в мозгу, нейроном называют обычную функцию, которая принимает на вход несколько чисел и что-то с ними делает, после чего – отправляет на выход. Связи – это входы, которые имеют веса. Вес – это множитель, который что-то делает с числом, когда то проходит по входу. Например, если вес связи (входа) равен 0.5, то число 10, проходя из нейрона в следующий по этой связи, будет поделен на 2, то есть умножен на 0.5. Нейроны для удобства размещают слоями – внутри слоя нейроны не имеют между собой связей, но имеют связи с предыдущим и последующим слоем.
А в чем заключается обучение? Оно кроется в весах. Например, у нас есть изображение 200х200 пикселей, на котором изображена цифра «4». Каждый пиксель будет нейроном, итого – 40 000 входящих нейронов, которые будут по некоторым параметрам суммироваться, пока результирующим ответом не станет «4». Для того, чтобы научить нейронку определять цифру «4», мы будем показывать ей различные четверки картинками и говорить, что «правильный ответ – 4, распредели веса так, чтобы вышел правильный ответ».
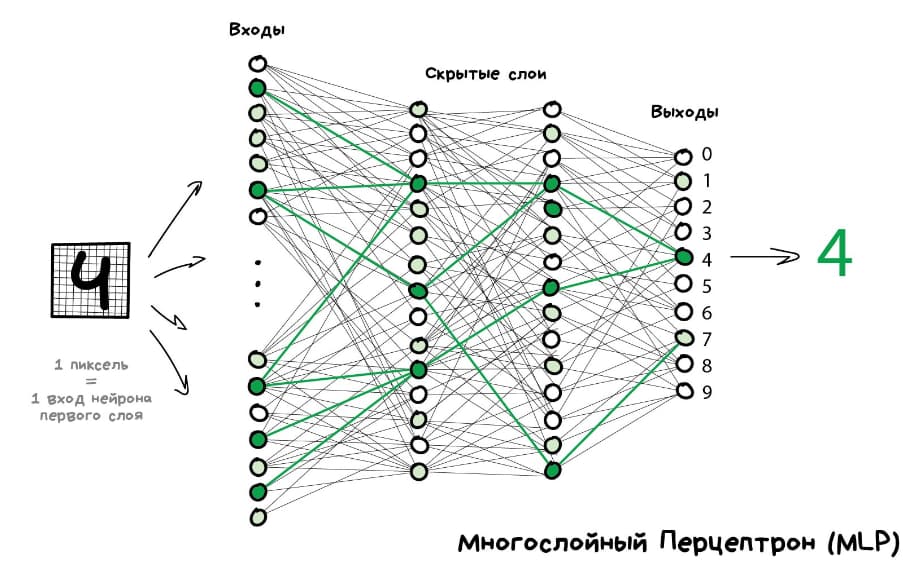
Естественно, в реальности все это работает сложнее, потому что приведенный выше алгоритм будет обучаться невероятно долго. Но общая концепция всегда одна: мы манипулируем числами и весами, чтобы научить нейронку определять правильный ответ.
Какие задачи решает
Все задачи, которые решает машинное обучение, сводятся к поиску закономерностей. Это, в свою очередь, можно разбить на 5 категорий:
- Регрессия. Предсказание следующего числового результата.
- Классификация. Разбиение объектов на классы по схожим признакам.
- Кластеризация. Классификация при наличии 3+ классов.
- Уменьшение размерности. Уменьшение количества «шумов» в данных за счет выделения «главных» переменных и отсечения «второстепенных».
- Выявление аномалий. Поиск данных, которые не попадают под выявленные закономерности.
Выявление аномалий – приятный побочный бонус, который может натолкнуть на мысль о том, что есть некоторое правило, которое еще не было найдено.
Области применения ML
Их – много. Прямо очень много. Вот поверхностный список вещей, которые можно делать с помощью машинного обучения:
- создание фильтров спама;
- определение языка написанного текста;
- распознавание голоса;
- поиск совпадений и схожестей в тексте;
- анализ транзакций;
- анализ кредитной истории и платежеспособности;
- прогноз стоимости чего угодно;
- выявление поломок;
- постановка диагнозов;
- анализ рынка;
- поиск зависимостей события от времени;
- разметка данных;
- построение маршрутов;
- пилотирование;
- и далее и далее.
Машинное обучение может применяться везде, где есть данные, а в данные можно преобразовать вообще все. Единственный вопрос, который стоит себе задавать: целесообразно ли применять ИИ для решения проблемы. Для того, чтобы научить машину находить закономерности и принимать решения, нужно собрать и категоризировать много данных, а потом дождаться, когда машина научится находить в них логику. Если задача – решить мировую проблему голода, то это может быть оправдано. Если задача – выбрать, чай или кофе вы предпочтете завтра утром, то затраченные усилия могут не стоить результата.
Как создается ИИ
Для того, чтобы создать ИИ, нужно последовательно пройти через 7 шагов:
- Определение задач и целей. Какую проблему вы будете решать? Что вы должны получить в итоге?
- Сбор данных. Это – самый большой и сложный шаг. Результат напрямую зависит от того, насколько много будет данных и насколько хорошо они будут систематизированы.
- Выбор модели/алгоритма. Когда вы будете видеть перед собой данные – вы сможете понять, каким именно образом вы сможете решить задачу наиболее быстро и эффективно.
- Обучение. Когда есть и данные, и алгоритм – вы просто оставляете их наедине и ждете результата.
- Оптимизация/тестирование. Когда модель обучилась – вы смотрите, насколько хорошо она это сделала. Если вас что-то не устраивает – дорабатываете модель и снова отправляете на обучение.
- Внедрение. Если вы работаете над крупным проектом – ИИ нужно будет в него встроить.
- Мониторинг/улучшение. Собираете статистику, наблюдаете работоспособность. Если что-то пошло не так – отправляете на доработку.
FAQ
Где искать информацию по машинному обучению?
Начните с Ютуба, вот на этой странице вы найдете множество обучающих плейлистов. Затем можно переходить к бесплатным курсам – увы, большинство из них на английском. Если вам действительно понравится эта область – после бесплатных курсов можете переходить на курсы машинного обучения.
Курс «Data Scientist с нуля до Junior» от Skillbox
Школа |
Skillbox |
Стоимость |
72 232 руб |
Цена в рассрочку |
3 283 руб/мес |
Длительность курса |
9 месяцев |
Программа трудоустройства |
Есть |
Формат |
Запись лекций, Онлайн занятия с преподавателем |
Курс «Machine Learning Engineer» от Академия «Синергия»
Школа |
Академия «Синергия» |
Стоимость |
141 520 руб |
Цена в рассрочку |
5 897 руб/мес |
Длительность курса |
9 месяцев |
Программа трудоустройства |
Есть |
Формат |
Запись лекций, Онлайн занятия с преподавателем |
Курс «Машинное обучение: фундаментальные инструменты и практики» от Нетология
Школа |
Нетология |
Стоимость |
38 500 руб |
Цена в рассрочку |
2 250 руб/мес |
Длительность курса |
10 месяцев |
Программа трудоустройства |
Отсутствует |
Формат |
Запись лекций, Онлайн занятия с преподавателем |
Нужно ли высшее образование для работы по специальности «разработчик ML»?
Высшее – точно не нужно, но желательно пройти серьезные курсы с «корочками» и знаниями из вышмата и статистики. Ну и приготовьтесь много учиться самостоятельно, машинное обучение – это динамичная область, в которой всегда нужно быть в курсе последних разработок.
Вывод
Тезисно:
- Машинное обучение – это вид искусственного интеллекта. Его особенность – в том, что модель может обучаться самостоятельно.
- В основе машинного обучения лежат данные, признаки и алгоритмы.
- Самое простое и неприхотливое ML – это классические модели с учителем. При этом на них строится одна из самых эффективных моделей машинного обучения – ансамблевая.
- Нейросети – это сети, в которых алгоритмы объединены связями, имеющими вес. Суть нейросети – обучиться выставлять правильные веса, опираясь на известные правильные ответы.
- Несмотря на то, что нейросети – самый «распиаренный» ИИ, их применяют не так уж и часто, потому что нейросети едят очень много ресурсов.
- Машинное обучение можно применить практически везде, где есть данные, единственный вопрос – целесообразно ли их применять, потому что машинное обучение обычно требует много ресурсов.