Как составлять регулярные выражения – короткий гайд по основам
Регулярное выражение – это шаблон, по которому специальный движок ищет совпадения в тексте. Регулярные выражения крайне удобны, потому что вы можете найти, например, специфическую ошибку в логах с парой миллионов строк; с другой стороны, многие ненавидят регулярки, потому что у них – не самый простой синтаксис, и при составлении регулярного выражения крайне просто ошибиться, получив вообще не тот результат, на который вы рассчитывали изначально. Ниже – гайд по основам составления регулярных выражений: после него вы не станете гуру регулярок, но сможете использовать их в распространенных задачах – валидация, санация входных данных, поиск конкретной строки и так далее.
Как пользоваться регулярками?
Краткое примечание: мы пишем гайд по применению регулярных выражений без привязки к языку, потому что правила и инструменты во всех языках +/- одинаковые.
Итак, для того, чтобы воспользоваться регулярным выражением, нам нужны: а) текст для поиска; б) регулярное выражение. Во многих языках регулярные выражения представляют собой объект, который хранит само выражение в строке, например:
regularExpression = new RegExp("регулярное выражение", "флаги");
Первый аргумент, который мы здесь передаем – это паттерн, которому должна соответствовать последовательность символов в исходном тексте для того, чтобы засчиталось совпадение.
Базовая единица паттерна – символ
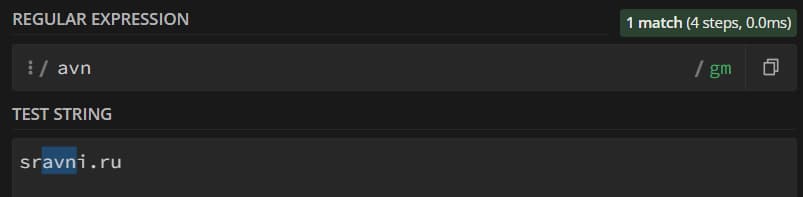
Если вы в качестве шаблона для регулярного выражения передадите строку из одного символа, например – «а», то будут найдены все буквы «а» в тексте. При этом «А» найдены не будут – если мы не передаем флаг «i» в регулярку, то регистр имеет значение. Если мы пишем несколько символов в строке регулярки – мы получаем подстроку, и эта подстрока должна встретиться в основной строке для того, чтобы было засчитано совпадение: выражение «avn» будет найдено в строке «sravni.ru»:
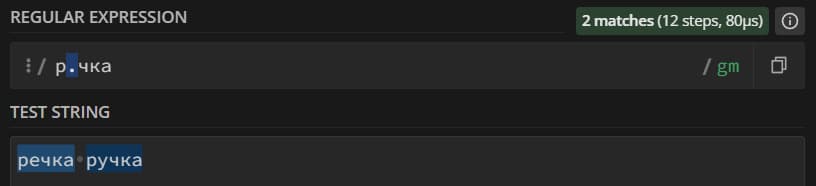
Искать конкретные символы – полезно, но настоящая сила регулярных выражений раскрывается, когда мы начинаем искать группы символов. Первый инструмент, который вам нужно освоить – мета-последовательности. Суть – в том, что при использовании мета-последовательности мы ищем не конкретный символ, а любой символ, входящий в последовательность. Самая широкая мета-последовательность – «.», она означает «любой символ, кроме перевода строки»:
Мета-последовательностей – много, но вам для начала нужно знать 4:
- «.». Описали выше.
- «\d». Любая цифра.
- «\s». Любой пробельный символ.
- «\w». Любая буква или цифра, а также знак «_».
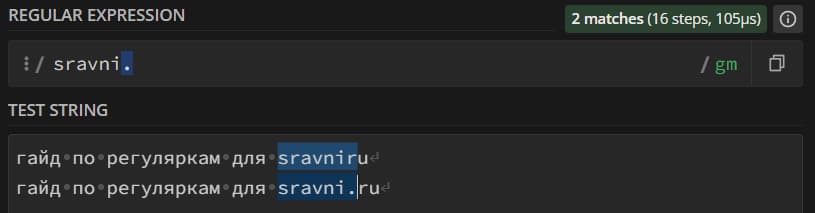
«.» – это не только мета-последовательность, но еще и мета-символ – символ, который для regexp значит что-то особенное. В regexp есть ряд мета-символов, вы познакомитесь с ними по мере изучения технологии: «.», «+», «*», «\» и далее по списку. Но вот проблема: если вы ищете в тексте точку («.»), и напишете регулярку с точкой, то получите не тот результат, на который рассчитывали:
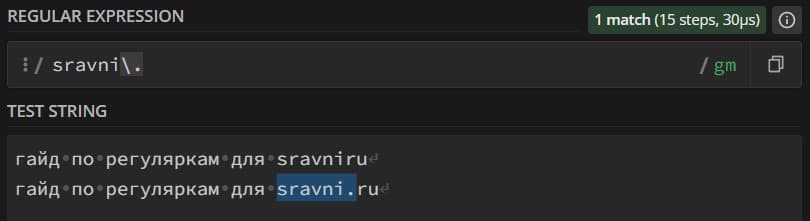
Для того, чтобы решить проблему, вам нужно использовать экранирование. Экранирование – это когда мы добавляем «\» перед мета-символом для того, чтобы превратить его в «обычный» символ:
Экранировать можно любой мета-символ, даже символ экранирования – если в тексте нам нужно найти символ «\», в регулярном выражении нужно написать «\\».
Ищем диапазоны символов
Мета-последовательности – это хорошо, но что делать, если в базовом арсенале регулярок нет нужной нам? Например, \d ищет все цифры, а нам нужны конкретно цифры 2, 3 и 5? В этом случае нам нужно создать свою последовательность, для чего есть 2 инструмента – диапазоны и группы.
Диапазоны задаются в квадратных скобках. Если вы перечисляете внутри квадратных скобок несколько символов – regexp расценивает это как «любой символ из диапазона в количестве одной штуки». Вместо перечисления символов можно задавать диапазоны символов: [0-5] – любая цифра от 0 до 5; [в-р] – любая строчная буква от в до р. Внутри квадратных скобок можно задать несколько диапазонов: [0-5в-р].
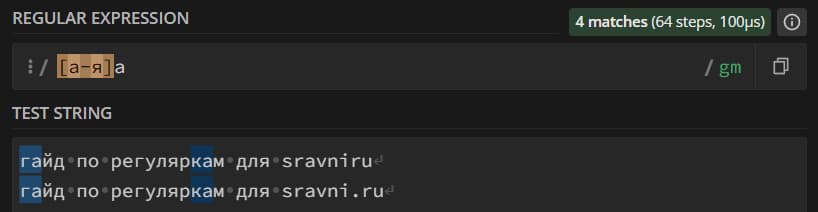
Из важного: внутри диапазонов нужно экранировать мета-символы конкретно для диапазонов («-», например); если вставить «^» первым символом группы, то получим отрицание.
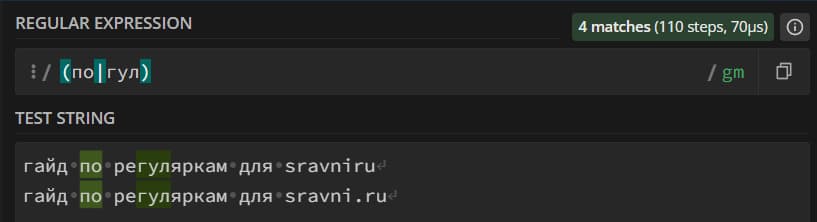
Группы же обозначаются круглыми скобками. Внутри группы мы можем указать несколько паттернов, разделив их знаком логического «или» («|»), и regexp будет искать любые совпадения одного из шаблонов. Группы полезны тем, что позволяют искать совпадения разной длины:
Наконец, последний инструмент, который вам нужен для составления регулярок – квантификаторы. Квантификатор позволяет повторить символ, диапазон или группу несколько раз подряд. Квантификатор задается либо мета-символом, либо диапазоном через {}. Мета-символы:
- *: повторяется любое количество раз.
- +: повторяется 1 или больше раз.
- ?: повторяется 0 или 1 раз.
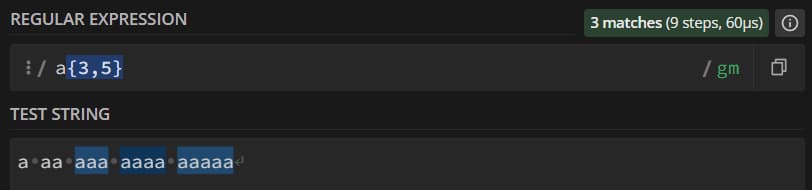
Диапазон задается синтаксисом {a, b}, где а – минимальное количество раз, которое должен повториться паттерн, а b – максимальное количество раз. Если пишем {a,} – паттерн должен повториться как минимум a раз, максимального предела нет. Если пишем {a} – диапазон должен повториться конкретно a раз.
Учитываем контекст
Есть пара специфических инструментов, которые могут помочь вам уточнить поиск – эти инструменты смотрят на контекст строки. Первая группа инструментов – якоря: если вы ставите «^» первым символом регулярки – значит, выражение должно быть в самом начале строки; если вы ставите «$» последним символом – значит, выражение должно быть в самом конце сроки. Соответственно, регулярка «^выражение$» должна занимать всю строку. Еще один крайне полезный якорь – «\b», он указывает на границу слова.
Второй инструмент – это lookahead. Он работает как «if» в языках программирования: если после совпадения по основному выражению есть дополнительное выражение/нет дополнительного выражения, то совпадение найдено. Синтаксис:
- основное_выражение(?=дополнительное_выражение) – основное выражение будет считаться совпадением, если после него есть дополнительное.
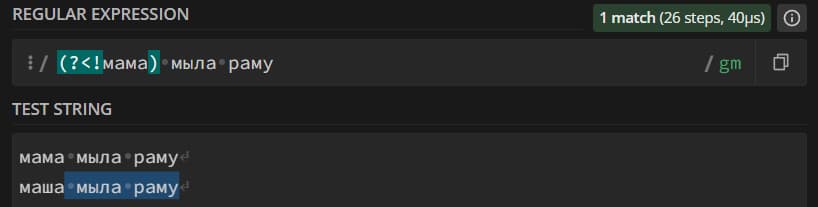
- основное_выражение(?!дополнительное_выражение) – основное выражение не будет считаться совпадением, если после него есть дополнительное.
- (?<=дополнительное_выражение)основное_выражение – основное выражение будет считаться совпадением, если перед ним есть дополнительное.
- (?<!дополнительное_выражение)основное_выражение – основное выражение не будет считаться совпадением, если перед ним есть дополнительное.
Какие регулярные выражения используются чаще всего?
5 примеров регулярок, которые вы будете часто встречать в работе:
- \b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b – регулярка ищет адреса электронной почты по широкому шаблону.
- \b\d{3}[-.]?\d{3}[-.]?\d{4}\b – телефонные номера из 10 чисел.
- https?://(?:www\.)?[^\s/$.?#].[^\s]* – url-адреса, подходит для протоколов http и https.
- \b\d{2}/\d{2}/\d{4}\b – дата в формате дд/мм/гггг.
- \b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b – ip-адреса.
Вывод
Тезисно:
- Регулярное выражение ищет совпадения по шаблону в тексте.
- Базовая единица регулярного выражения – символ, но можно искать не конкретный символ, а любой из группы/диапазона.
- Квантификаторы позволяют искать повторяющиеся последовательности символов.
- При поиске совпадений можно учитывать контекст – якоря начала/конца строки/слова, например.